고정 헤더 영역
상세 컨텐츠
본문
게임 텍스트 번역이라는 과제에서 LLM이 가지는 장점
바야흐로 LLM(Large Language Model)의 시대가 도래했고, 오픈소스 모델들이 속속들이 등장하면서 누구나 집 컴퓨터에서 딸각(과 코드 몇 백 줄을 작성)하면 텍스트 관련한 귀찮은 일들을 모두 AI한테 맡길수 있는 세상이 왔습니다. 나무가 충분히 자란것 같으니 이제는 슬슬 열매를 따먹어봐야할 시간이 온거지요.
그래서 저는 그동안 머릿속으로 상상만하고 여력이 없어서 이루지 못한 일들을 AI발달에 힘입어 하나씩 이뤄나가보려고 하는데요, 첫번째 타겟은 게임 텍스트 자동 번역입니다. 자동 번역은 이미 충분히 발달된 분야가 아닌가 생각하실 수 있겠지만, 게임 텍스트 자동 번역은 생각보다 난이도가 있는 과제입니다.
먼저 게임 내 세계관에서만 사용되는 고유명사가 굉장히 많기 때문에 이를 일관되게 번역하기가 쉽지 않습니다. 예를 들어 hybrid라는 단어는 일반적으로 혼합, 잡종 등의 의미로 쓰이지만 스타크래프트 세계관에서는 이를 "혼종"이라는 말로 번역하고 있습니다. 만약 스타크래프트 세계관의 텍스트를 번역한다면 hybrid를 "혼종"이라고 일관되게 번역해야겠지만 일반 번역기를 이를 해내지 못합니다.
둘째로 게임 내 캐릭터들의 대사의 경우 청자와의 관계, 캐릭터의 성격 등에 따라 알맞은 어조로 번역되어야 하는데 이 역시 어렵습니다. 일반적으로 존댓말을 쓰지만, 친한 관계인 B에게만 반말로 이야기하는 캐릭터 A의 대사를 자동 번역하는 상황을 생각해보면 되겠습니다. 일반 번역기에서는 말투가 제멋대로 섞인 번역결과가 나오게 되겠죠. 이는 영화나 연극 스크립트 등을 번역할때도 자주 마주하는 문제입니다.
마지막으로 게임 텍스트는 그 특성상 다양한 서식지정자나 채움문자(placeholder) 등과 함께 쓰이는 경우가 많은데 이를 그대로 유지하면서 번역하기가 쉽지 않습니다. 텍스트에 강조를 표시하거나 색상을 바꾸기 위해 게임마다 고유한 서식지정자를 사용하기도 하고 (예시: "[Surprise 55]The crystal is free of defenders.[/Surprise] Our warriors can destroy it whenever you are ready!"), 상황에 따라 들어가는 텍스트가 바뀌는 경우를 대비해 채움문자를 사용하기도 합니다 (예시: "Good morning {PlayerName}, what can I do for you?"). 이런 서식지정자나 채움문자는 정확하게 원본형태를 유지해야지만 프로그램에서 이를 올바르게 처리할 수 있는데, 번역기들은 이 마저도 번역 대상으로 간주하거나 아니면 번역 시에 빼버리는 만행을 저지르곤 합니다. 이래서야 자동 번역을 전혀 써먹을수가 없죠.
하지만 LLM은 적당한 예제를 몇 가지 보여주면 예제와 비슷하게 작업을 해내는 In Context Learning(ICL)이라는 능력을 가지고 있기 때문에 많은 품을 들이지 않고도 위의 3가지 문제를 해결하는게 가능합니다(당연히 완벽하지는 못하고 다양한 하이퍼파라미터 조합을 탐색해야하는 등 번거로운 일들도 있지만 별도의 시스템을 새로 개발하는것보다는 쉽습니다).
대상 게임: Starcraft Mass Recall에 포함된 Dark Vengeance
대상으로 잡은 것은 스타크래프트2에 나온 스타1 시절 캠페인 모드인 Starcraft Mass Recall, 그 중에서 Dark Vengeance입니다. 이걸 설정한 이유는 스타1~2 (준) 공식 캠페인 중 유일하게 플레이해보지 않은거라 한번 해보고 싶다는 생각을 가지고 있었는데 막상 해보니 영어의 압박에 즐겜하기가 쉽지 않았기 때문이죠~ 옛날 같으면 그냥 참고 했겠지만 현지화 잘된 스타2 캠페인들을 하다가 Full text English를 보려고 하니 도저히 참을 수가 없었습니다.
다행히도 스타1~2는 내부 구조가 잘 파헤쳐져 있고, 특히 스타2의 경우 유저가 손쉽게 Mod를 제작할 수 있게 게임 차원에서 원할하게 지원하고 있기 때문에 ICL에 사용할 텍스트를 추출하고 텍스트/폰트 등을 교체하는게 쉽다는것도 선택의 요인 중 하나였습니다.
대상 모델
- Llama3.1 8B Instruct: Meta(페이스북)에서 공개한 LLM. 사실상 오픈 LLM의 대표 주자입니다. 다만 학습 데이터가 영어에 치우쳐져 있어 한국어 능력이 다소 떨어진다고 알려져 있습니다.
- Bllossom 8B (Instruct): 서울과기대, 테디썸, 연세대 언어자원 연구실이 협업해 공개한 LLM. Llama3에 한국어 어휘를 확장하여 한국어 능력을 강화시킨 버전입니다.
- Qwen2 7B Instruct: 중국 알리바바에서 공개한 LLM. Llama가 미국의 대표 오픈 LLM이라면 Qwen은 중국의 대표 오픈 LLM이라 볼 수 있습니다. 학습 데이터가 영어/중국어에 치우쳐져 있어 한국어가 다소 약하다고 합니다.
- Solar Ko Recovery 11B (PLM): 이준범(Beomi)님이 학습시킨 LLM으로 Upstage에서 공개한 Solar 모델에 한국어 능력을 강화시킨 버전입니다. 이 모델은 나머지 모델들과 다르게 인스트럭션 튜닝이 되지 않은 모델입니다. 그래서 자연어로 구성된 지시사항을 잘 이해하지 못하고 텍스트를 이어서 생성하는 능력만 가지고 있습니다.
- Mistral 12B Instruct: 프랑스의 Mistral과 NVIDIA가 협업하여 개발한 LLM. 다국어를 지원한다고 알려져 있습니다.
- EXAONE 3.0 8B Instruct: LG AI Research에서 개발한 LLM. 한국어와 영어를 중점적으로 학습했다고 합니다.
테스트 시점에서 한국어가 가능한 최신 모델들을 다양하게 모아봤습니다. 데스크톱 GPU의 VRAM이 16GB인 관계로 FP8로 inference를 돌린다해도 12B 정도가 가능한 최대 크기인듯하더라구요. 더 큰 모델을 쓰면 더 좋았겠지만 이 정도 지점에서 현실적으로 타협했습니다.
프롬프팅 포맷
번역 요청을 내릴때 어떤 형식으로 요청을 내리는지에 따라 모델이 동일하더라도 결과 품질이 크게 달라질 수 있습니다. 따라서 다양한 포맷을 시도해보며 제일 말을 잘 듣는 포맷을 찾는게 필수적입니다. 이번 실험에서 시도한 포맷은 다음과 같이 3종류입니다. A1~An은 영어 문장, B1~Bn은 각 영어 문장에 대응하는 한국어 번역 문장입니다. 그리고 Ax는 우리가 실제로 번역하고 대상 영어 문장이구요. A1~An이 B1~Bn으로 번역된다는 사실을 먼저 모델에게 예제로 보여주고 Ax를 번역하라고 시킬 것입니다. Instruction 모델에게 전달하는 입력 텍스트는 크게 System, User, Assistant의 3가지 역할로 구분되는데, 아래에서 이 역할에 해당하는 텍스트는 각각 <System>, <User>, <Assistant>라는 접두사를 붙여서 표시했습니다. 흔히 System은 AI모델 전체에게 내리는 지시사항을 나타내는 역할을, User는 유저가 AI모델에게 요청한 텍스트, Assistant는 AI모델이 유저에게 응답한 텍스트를 나타내는 역할을 합니다.
Default
<System> Please translate the following English text to Korean.
<User> Input: A1
Output: B1
Input: A2
Output: B2
...
Input: An
Output: Bn
Input: Ax
Output:
가장 기본적인 형태는 System 프롬프트로 번역하라는 지시사항을 주고, User 입력으로 Input, Output 예제를 차례로 준 뒤 마지막으로 우리가 번역하길 원하는 Input을 줍니다. 그러면 다음 턴에서 Assistant는 Output: 뒤에 이어질 텍스트를 생성하겠죠.
Alternative
<System> Please translate the following English text to Korean.
<User> A1
<Assistant> B1
<User> A2
<Assistant> B2
...
<User> An
<Assistant> Bn
<User> Ax
형태를 바꿔서 Input, Output이라는 구질구질한 접두어를 생략하고, User턴에 Input을, Assistant턴에 Output을 번걸아가며 넣었습니다. 그리고 마지막 User턴에 우리가 번역하길 원하는 Input을 줍니다. 그러면 다음 턴에서 Assistant는 Input에 대한 번역 결과를 생성할 겁니다. 주목해야할 사항은 중간에 들어가는 Assistant턴들입니다. 이 턴은 실제로 모델이 생성한 결과는 아니지만 Assistant의 역할로 모델에게 입력되므로, 모델은 유저가 A1을 입력했을때 자신이 B1이라고 답했고, 유저가 A2를 입력했을때 자신이 B2라고 답했다고 받아들이게 됩니다. 이는 오늘날 널리 쓰이는 decoder only 기반의 모델들은 태생적으로 기억력이라는게 전혀 없어서 다음 텍스트을 생성할때 오직 이전의 입출력 결과만을 기준으로 현재 상황을 판단하기 때문입니다. (영화 메멘토의 주인공마냥 기억상실증에 걸려서, 주변에 남겨진 기록들만 가지고 자신이 과거에 무엇을 했는지 판단하는 것이라고 보면 되겠습니다.) 따라서 위와 같이 프롬프트를 넣어주게 되면 모델은 실제로 그렇게 답한 적은 없지만 마치 과거에 자신이 그렇게 했다고 여기고 그런 상황에서 Ax가 입력되었을때 적절한 Bx를 생성하고자 노력하게 되겠죠.
Numbered
<System> Please translate the following English text to Korean.
<User> [1] A1
[2] A2
...
[n] An
[n+1] Ax
<Assistant> [1] B1
[2] B2
...
[n] Bn
[n+1]
이 포맷에서는 Input과 Output이 교대로 들어가는 대신 Input이 먼저 쭉 들어가고, Output이 쭉 나오는 형태로 구성해봤습니다. 마찬가지로 중간에 삽입된 Assistant 턴 덕분에 모델은 유저가 A1~An, Ax을 입력했을때 자신이 B1~Bn이라고 답했다고 받아들이게 됩니다. 그리고 생성 작업을 계속 이어서 그 다음 할일인 Bx를 생성하는 일을 자연스레 수행하게 될 겁니다.
예제 문장 선택하기
프롬프트를 구성할때 사용할 영어, 한국어 문장 예제 문장(An, Bn)을 어떻게 선택하느냐도 성능에 중요한 영향을 미칠 겁니다. 직관적으로 생각해볼 때 번역하려고 하는 문장 Ax와 유사한 An들을 가져오는게 실제 번역 작업에 도움이 될 것이라는건 자명합니다. 유사한 문장을 검색하는 방법에는 크게 키워드 검색(Keyword Search)과 벡터 검색(Vector Search, =시맨틱 검색, Semantic Search)이 있는데요, 최근 딥러닝 방식 검색이 대두되면서 검색하면 일단 벡터 검색부터 떠올리는 경우가 많습니다. 그런데 지금과 같은 상황에서는 키워드 검색이 더 유용합니다. 우리는 특정 단어가 어떻게 번역되는지 예제 문장을 보는게 필요하므로 단어별 일치가 잘 되는 유사 문장을 찾아야하기 때문입니다. 그래서 아주 전통적인 BM25 검색을 사용해서 예제 문장을 찾기로 했습니다.
예제 문장은 10개 정도 보여주면 적당할 것이라고 생각해서 개수를 10으로 고정했습니다(물론 엄밀하게 하려면 이것도 바꿔가보면서 실험해봐야겠지만 어디 논문 낼것도 아니니깐...). 근데 단순히 검색 한 번 해서 Top 10 문장만 뽑아오면 다 될까요? 테스트를 위해 "Focus on destroying targets that endanger the Odin, like Siege Tanks, Banshees, and Battlecruisers." 라는 문장을 입력으로 Top 10을 뽑아보면 다음과 같습니다.
| 순위 | 영어 | 한국어 |
|---|---|---|
| 1 | Laser Targeting System Siege Tank | 레이저 조준 시스템 공성 전차 |
| 2 | Focused Siege | 집중 공성 공격 |
| 3 | Siege Tank (Sieged) | 공성 전차 (공성 모드) |
| 4 | Siege Tank Sieged | 공성 전차 공성 모드 |
| 5 | {Siege Tank} - You may now build {Siege Tank} from the {Factory}. | {공성 전차} - 이제 {군수공장}에서 {공성 전차}를 생산할 수 있습니다. |
| 6 | {Siege Tank} -- You may now build a {Siege Tank} from the {Factory}. | {공성 전차} -- 이제 {군수공장}에서 {공성 전차}를 생산할 수 있습니다. |
| 7 | Siege Tank Merc Veterancy Aura Target Bonus | 공성 전차 용병 실전 경험 오라 대상 보너스 |
| 8 | Commando Siege Tank | 코만도 공성 전차 |
| 9 | CRUCIO SIEGE TANK | 크루시오 공성 전차 |
| 10 | Hover Siege Tank | 체공 공성 전차 |
키워드 검색 특성 상 드물게 등장하는 단어가 많이 겹칠수록 높은 점수를 받아서 검색 순위 상위에 위치하게 됩니다. 이 때문에 Siege Tank라는 표현이 높은 점수를 받게 되어서(고유명사지만 혼자서 2단어입니다), 검색 결과 상위 10개 안에 모두 Siege Tank와 관련된 단어만 나왔습니다. 모델이 이걸 예제로 보고 번역을 실시하면 Siege Tank는 공성 전차라고 바르게 번역하겠지만, Odin, Banshees, Battlecruisers는 어떻게 번역해야할지 모르겠죠. 그래서 검색 1번에 모든 결과를 가져오는 대신 그룹을 나눠서 여러 번 결과를 가져오는 방법을 떠올려 봤습니다. X와 유사한 문장 n개를, 총 g개의 그룹으로 가져오는 절차는 다음과 같습니다.
- X를 검색어로 던져서 n/g개의 예제를 가져온다.
- 가져온 예제 문장에 포함된 단어들은 X에서 제거한다.
- 1~2번을 총 g번 반복한다.
- 가져온 예제 문장을 모아서 총 n개의 예제 문장을 확보한다.
이 절차를 통해 3개 그룹으로 총 10개의 예제 문장을 가져오면 다음과 같이 되겠습니다.
| 그룹-순위 | 영어 | 한국어 |
|---|---|---|
| 1-1 | Laser Targeting System Siege Tank | 레이저 조준 시스템 공성 전차 |
| 1-2 | Focused Siege | 집중 공성 공격 |
| 1-3 | Siege Tank (Sieged) | 공성 전차 (공성 모드) |
| 2-1 | The Odin has been destroyed. | 오딘이 파괴되었습니다. |
| 2-2 | Sir, I'm picking up Dominion battlecruisers on an intercept course with the Odin. | 대장님, 자치령 전투순양함이 오딘 쪽으로 향하는 걸 감지했습니다. |
| 2-3 | So Swann, what're the chances we can build something like that Odin? | 아... 스완, 우리도 오딘 같은 걸 자체 생산할 수 있을까요? |
| 2-4 | A Molten Salamander has emerged from the lava! Conservationists say they're endangered, but who's in danger now? | 용암 도롱뇽이 용암 속에서 나타났습니다! 환경 보호론자들은 이것이 멸종 위기종이라 하지만, 지금은 누가 진짜 멸종 위기일까요? |
| 3-1 | BANSHEE | 밴시 |
| 3-2 | Has Banshees | 밴시 있음 |
| 3-3 | Banshee | 밴시 |
첫번째 검색 결과에서는 1-1 ~ 1-3 문장을 가져옵니다. 이후 검색 결과에 포함된 Siege Tank 등의 단어를 검색어에서 제거하고 다시 검색을 수행하면 2-1 ~ 2-4의 결과가 나옵니다. 마찬가지로 2-1 ~ 2-4에 포함된 단어들을 검색어에서 제거하고 다시 검색을 수행하면 Banshee만 남아서 3-1 ~ 3-3과 같은 결과를 얻습니다. 이렇게 10개의 예제 문장을 구성하면 모델이 Siege Tank뿐만 아니라 Odin, Banshee, Battlecruiser와 같은 고유 명사도 어떻게 번역해야하는지 잘 알수 있을 겁니다.
| 그룹-순위 | 영어 | 한국어 |
|---|---|---|
| 1-1 | Laser Targeting System Siege Tank | 레이저 조준 시스템 공성 전차 |
| 1-2 | Focused Siege | 집중 공성 공격 |
| 2-1 | The Odin has been destroyed. | 오딘이 파괴되었습니다. |
| 2-2 | All of your banshees have been destroyed. | 모든 밴시가 파괴되었습니다. |
| 3-1 | Battlecruiser | 전투순양함 |
| 3-2 | Brood Lords are particularly vulnerable to flying units like Battlecruisers, Vikings, and Wraiths. | 무리 군주는 전투순양함, 바이킹, 망령 같은 공중 유닛에 특히 약합니다. |
| 4-1 | A Molten Salamander has emerged from the lava! Conservationists say they're endangered, but who's in danger now? | 용암 도롱뇽이 용암 속에서 나타났습니다! 환경 보호론자들은 이것이 멸종 위기종이라 하지만, 지금은 누가 진짜 멸종 위기일까요? |
| 4-2 | Units on higher ground can attack without endangering themselves. To counter this, gain vision of the attackers by running up ramps or bringing air units. | 고지대에 있는 유닛들은 공격을 받지 않으면서 적을 공격할 수 있습니다. 이에 대응하려면 비탈길로 올라가거나 공중 유닛을 데려와서 시야를 확보해야 합니다. |
| 5-1 | Laser Targeting System Banshee | 레이저 조준 시스템 밴시 |
| 5-2 | Nothin' like getting' TANKED with your buddies! | 친구들하고 폭탄 돌리는 것만 한 게 있나! |
그룹 개수를 5개로 늘리면 위와 같이 될거구요. 너무 많이 늘리게 되면 검색에 이상한 결과들이 잡힐수도 있으니 실험을 통해 적당한 값을 잡는게 중요해보이겠습니다.
검색시에 추가로 고려하면 또 좋은 것이 바로 화자(Speaker) 정보입니다. 똑같은 Hi?라는 영어 문장이라도 누가 말했는지에 따라 한국어로는 "안녕?", "안녕하시오?", "안녕하십니까?" 등 다양하게 옮겨질 수 있습니다. 그래서 문서를 색인하는 단계에서 화자 정보라는 카테고리를 주고, 옵션에 따라서 해당 화자 정보 내에서만 검색을 수행할 수 있게 하였습니다. 그래서 똑같이 Hi?라는 문장을 검색해도 이 대사가 Zeratul의 것이면 Zeratul의 대사 내에서만 Hi를 검색하고, Raynor의 것이라면 Raynor의 대사 내에서만 Hi를 검색하는 식으로 하여 검색 결과가 달라지게 하였습니다.
실험
번역 성능을 평가하기 위해서는 평가 데이터셋이 있어야합니다. 이를 위해 스타크래프트2 내의 LocalizationData에서 영어 텍스트와 한국어 텍스트 60183쌍을 추출했습니다. 이 중 세 단어 이상으로 구성된 문장 2000쌍을 랜덤하게 골라 평가셋으로 설정했고 나머지는 ICL에 사용할 Few shot 예제 문장으로 설정했습니다. 평가셋에는 Few-shot 예제 문장에 있는 문장과 너무 동일한 문장(문장 간 차이가 단어 한 개 이하인 경우)은 들어가지 않도록 배제했습니다.
추출된 Few shot 예제 문장과 평가셋 일부를 보여드리자면 다음과 같습니다.
| src | id | speaker | en | ko |
|---|---|---|---|---|
| campaigns/ swarmstory.sc2campaign |
Conversation/ zMission_Zerus02/Line00158 |
Kerrigan | Here they come. | 놈들이 온다. |
| campaigns/ swarmstory.sc2campaign |
UserData/ CampaignTips/Siege Tanks_Name |
- | Siege Tanks | 공성전차 |
| campaigns/ liberty.sc2campaign |
Achievement/ Name/AiurChef_05 |
- | Allez Cuisine! | 요리의 모든 것! |
| mods/ liberty.sc2mod |
Skin/Info/ TempestIhanrii |
- | The dampening effect of the Ihan-rii tempest's stone surface enhances its ability to focus the incredible power output of its kinetic matrix. | 이한 리 폭풍함 석재 장갑의 완충 효과는 키네틱 매트릭스의 무시무시한 정격 출력 집중 능력을 향상시켜 줍니다. |
| mods/ starcoop/starcoop.sc2mod |
Button/ Tooltip/ACSwannEngineeringBayUpgraded |
Tooltip | Contains upgrades for structures. <n/><n/><c val="ffff8a">Enables:</c><n/>- Spinning Dizzys from SCVs | 구조물을 업그레이드합니다.<n/><n/><c val="ffff8a">사용 가능:</c><n/>- 회전 화포 (건설로봇 건설) |
| campaigns/ voidstory.sc2campaign |
Conversation/ Convo_Communicator/Line00078 |
Artanis | Zeratul found me. It was there that he... he... | 그때 제라툴이 날 발견했고, 그곳에서 그는... 그는... |
| campaigns/ libertystory.sc2campaign |
Conversation/ BridgeTychus/Line00003 |
Raynor | Well, so ya thinking about giving up this life of luxury and becoming a professional broadcaster? | 자네, 이러다가 다 집어치우고 전문 방송인으로 나가는 거 아닌가? |
| campaigns/ swarmstory.sc2campaign |
Conversation/ zMission_Korhal03/Line00021 |
Mengsk | This is my world, Kerrigan. You are not welcome here! | 여긴 내 세상이다, 케리건. 너는 불청객일 뿐이야. |
| campaigns/ voidstory.sc2campaign |
Conversation/ pConvo_TaldarimHero/Line00143 |
TaldarimHero | [Happy 80]Such hubris.[/Happy] [Surprise 60]To think that they could control[/Surprise] what [Angry 60]they did not understand.[/Angry] | [Happy 80]오만하기도 하지.[/Happy] [Angry 60]알지도 못하는 걸[/Angry] [Surprise 60]통제할 수 있다고 믿다니.[/Surprise] |
평가셋은 구글 스프레드시트 페이지에서 살펴볼 수 있습니다.
평가 척도로는 자동 번역을 평가할때 흔히 쓰이는 ROUGE를 사용하기로 했습니다. ROUGE에 대해 자세히 알고 싶으시다면 이 글을 읽어보시길 추천드립니다. ROUGE에서는 모델이 번역해낸 문장이 정답 문장과 얼마나 일치하는지를 기계적으로 평가하는데, 일반적으로 단어 단위로 일치여부를 계산합니다. 그런데 단어 단위의 평가는 영어 문장에는 잘 통하지만 한국어에서는 어미/조사 등의 문제 때문에 잘 통하지 않습니다(e.g. 했습니다/하였습니다, 레이너가/레이너는 : 이런 경우는 의미적으로 동일하거나 유사하지만 단어 단위의 비교에서는 완전히 다른것으로 판단됩니다). 그래서 최종적으로는 글자를 단위로 한 Chr ROUGE와 형태소를 단위로 한 Morph ROUGE를 사용했습니다. 특히 Morph ROUGE를 계산할때는 [Happy 80]이나 <c val="ffff8a">같은 서식지정자 혹은 채움문자는 모두 한 토큰으로 분석되도록 형태소 분석기의 옵션을 손봤습니다. 이런 서식지정자나 채움문자는 한 글자라도 달라지면 그 의미가 아예 달라지므로 토큰 내 문자열이 완전 일치한 경우만 맞았다고 판단할 수 있기 때문입니다.
실험 결과 - 요약
본격적인 실험에 앞서 베이스라인이 어느정도인지 확인해봐야겠죠? 번역 예제 데이터를 전혀 주지 않은 경우(Zero-shot)와 파파고와 DeepL 번역기를 사용했을 때의 번역 성능을 측정해보았습니다.
| 모델 | Chr ROUGE-2 | Chr ROUGE-3 | Chr ROUGE-L | Mor ROUGE-1 | Mor ROUGE-2 | Mor ROUGE-L | Elapsed Sec |
|---|---|---|---|---|---|---|---|
| Llama3.1 8B Inst | 0.3436 | 0.2338 | 0.4493 | 0.3697 | 0.1798 | 0.3295 | 158.69 |
| Bllossom 8B Inst | 0.3634 | 0.2489 | 0.4706 | 0.3847 | 0.1885 | 0.3443 | 156.71 |
| Qwen2 7B Inst | 0.3408 | 0.2300 | 0.4516 | 0.3873 | 0.1736 | 0.3469 | 163.26 |
| Solar Ko 11B | 0.0006 | 0.0001 | 0.0013 | 0.0000 | 0.0000 | 0.0000 | 31.27 |
| Mistral 12B Inst | 0.0326 | 0.0117 | 0.1280 | 0.0074 | 0.0028 | 0.0074 | 284.80 |
| EXAONE 3.0 8B Inst | 0.1722 | 0.1254 | 0.2794 | 0.1815 | 0.1001 | 0.1653 | 100.64 |
| PAPAGO (2024-08-24) | 0.4326 | 0.3111 | 0.5342 | 0.4493 | 0.2430 | 0.4086 | - |
| DeepL (2024-08-24) | 0.4723 | 0.3535 | 0.5693 | 0.5024 | 0.2966 | 0.4637 | - |
LLM의 경우 Zero-shot에서는 일반 번역기보다 크게 뒤떨어지는 성능을 보였습니다. 특히 Solar Ko Recovery 모델의 경우 인스트럭션 튜닝이 전혀되지 않아 사실상 성능이 0이라고 볼 수 있습니다. 그나마 Bllossom이랑 Qwen2가 조금이나마 쓸만한 성능을 보이고 있네요.
프롬프팅 포맷이 번역 성능에 얼마나 영향을 미칠까요? Solar Ko 11B의 결과를 통해서 살펴봅시다. Default 0는 위에서 보여줬던 Zero-shot 베이스라인 성능이고, 예제 개수가 0이 아닌 것들은 실제 ICL의 효과가 반영된 Few-shot의 결과입니다. 인스트럭션 튜닝이 되지 않은 Solar Ko모델은 Default 프롬프트에서는 예제를 아무리 주어도 전혀 번역을 못했지만, 포맷을 Alternative나 Numbered로 바꾸자 갑자기 말문이 터져나옵니다. Alternative, Numbered 포맷에서는 모든 경우에 파파고, DeepL보다 훨씬 나은 번역 성능을 보이며, 특히 예제 그룹이 3개일때 전반적으로 좋은 성능을 보여주었습니다.
| 프롬프팅 포맷 | 예제 개수 / 그룹 | Chr ROUGE-2 | Chr ROUGE-3 | Chr ROUGE-L | Mor ROUGE-1 | Mor ROUGE-2 | Mor ROUGE-L | Elapsed Sec. |
|---|---|---|---|---|---|---|---|---|
| Default | 0 | 0.0006 | 0.0001 | 0.0013 | 0.0000 | 0.0000 | 0.0000 | 31.27 |
| Default | 10 / 1 | 0.0203 | 0.0017 | 0.1246 | 0.0009 | 0.0003 | 0.0007 | 1649.35 |
| Default | 10 / 3 | 0.0234 | 0.0038 | 0.1300 | 0.0025 | 0.0011 | 0.0025 | 1231.26 |
| Default | 10 / 5 | 0.0232 | 0.0035 | 0.1301 | 0.0025 | 0.0010 | 0.0024 | 1216.85 |
| Alternative | 10 / 1 | 0.6058 | 0.5098 | 0.6683 | 0.6169 | 0.4447 | 0.5778 | 1705.69 |
| Alternative | 10 / 3 | 0.6095 | 0.5119 | 0.6705 | 0.6225 | 0.4448 | 0.5801 | 1269.33 |
| Alternative | 10 / 5 | 0.6116 | 0.5146 | 0.6739 | 0.6232 | 0.4484 | 0.5830 | 1304.94 |
| Numbered | 10 / 1 | 0.6045 | 0.5079 | 0.6671 | 0.6144 | 0.4412 | 0.5749 | 1666.70 |
| Numbered | 10 / 3 | 0.6112 | 0.5149 | 0.6740 | 0.6208 | 0.4479 | 0.5822 | 1318.63 |
| Numbered | 10 / 5 | 0.6097 | 0.5136 | 0.6726 | 0.6188 | 0.4454 | 0.5799 | 1351.18 |
화자 정보를 사용하는건 번역 품질이 얼마나 도움이 될까요? 동일하게 Solar Ko 모델에 프롬프팅 포맷을 Alternative로 고정하고 화자 정보를 사용한경우와 그렇지 않은 경우를 비교해보았습니다. 화자 정보를 사용한 경우가 모든 경우에서 일관성 있게 성능 향상을 보였습니다. 특히 10 / 3에서는 Mor ROUGE-L이 처음으로 60%를 넘기기도 했습니다.
| 예제 개수 / 그룹 | 화자 정보 | Chr ROUGE-2 | Chr ROUGE-3 | Chr ROUGE-L | Mor ROUGE-1 | Mor ROUGE-2 | Mor ROUGE-L | Elapsed Sec. |
|---|---|---|---|---|---|---|---|---|
| 10 / 1 | 미사용 | 0.6058 | 0.5098 | 0.6683 | 0.6169 | 0.4447 | 0.5778 | 1705.69 |
| 사용 | 0.6215 | 0.5268 | 0.6800 | 0.6330 | 0.4632 | 0.5930 | 1797.56 | |
| 10 / 3 | 미사용 | 0.6095 | 0.5119 | 0.6705 | 0.6225 | 0.4448 | 0.5801 | 1269.33 |
| 사용 | 0.6296 | 0.5355 | 0.6856 | 0.6433 | 0.4714 | 0.6017 | 1428.34 | |
| 10 / 5 | 미사용 | 0.6116 | 0.5146 | 0.6739 | 0.6232 | 0.4484 | 0.5830 | 1304.94 |
| 사용 | 0.6287 | 0.5340 | 0.6868 | 0.6405 | 0.4684 | 0.6002 | 1362.16 |
전반적으로 제일 좋은 성능을 보였던 조합인 Alternative 포맷, 예제 10개, 그룹 3개, 화자 정보까지 사용한 옵션으로 모든 모델의 번역 성능을 정리해봤습니다. 역시 LLM은 크기빨인지 Solar Ko 11B가 제일 높은 성능, 그 다음으로 Mistral 12B가 높은 성능을 보였네요. 7~8B 규모에서는 Llama3에 한국어 튜닝을 수행한 Bllossom이 제일 높은 성능을 달성했습니다. 한국어/영어 전용 모델인 EXAONE은 중국 모델에다가 크기도 살짝 작은 Qwen2와 거의 동일한 성능을 보여 아쉬움을 남겼습니다.
| 모델 | Chr ROUGE-2 | Chr ROUGE-3 | Chr ROUGE-L | Mor ROUGE-1 | Mor ROUGE-2 | Mor ROUGE-L | Elapsed Sec. |
|---|---|---|---|---|---|---|---|
| Llama3.1 8B Inst | 0.5963 | 0.4944 | 0.6631 | 0.6045 | 0.4210 | 0.5602 | 266.28 |
| Bllossom 8B Inst | 0.5982 | 0.4955 | 0.6649 | 0.6063 | 0.4215 | 0.5638 | 472.31 |
| Qwen2 7B Inst | 0.5847 | 0.4805 | 0.6529 | 0.5937 | 0.4041 | 0.5461 | 267.39 |
| Solar Ko 11B | 0.6296 | 0.5355 | 0.6856 | 0.6433 | 0.4714 | 0.6017 | 1428.34 |
| Mistral 12B Inst | 0.6114 | 0.5133 | 0.6750 | 0.6201 | 0.4405 | 0.5784 | 606.88 |
| EXAONE 3.0 8B Inst | 0.5776 | 0.4765 | 0.6462 | 0.5934 | 0.4082 | 0.5493 | 240.72 |
생성에 소요된 시간은 엄밀하게 측정된 것은 아니라 참고용으로만 보시길 바랍니다. 실험을 돌린 장비가 VRAM 16GB짜리라 10B 이상 모델은 간신히 올릴수 있고, 이 경우 특히 생성길이가 길어지면 KV Cache를 CPU RAM과 교환해가면서 생성을 해야해서 속도가 확 떨어지거든요. Solar Ko 11B가 유난히 오래 걸린것도 번역을 잘해서 생성길이가 길어지다보니 그런것이라 보시면 됩니다.
지면 상 실험 결과 전부를 담지는 못했지만 스프레드시트로 정리해둔게 있으니 관심 있으신 분들은 여기에서 자세한 결과를 확인하시길 바랍니다!
실험 결과 - 사례 분석
결과를 숫자로만 보면 재미가 없죠? 실제 번역된 문장들을 살펴봅시다.
| 영어 원문 | Focus on destroying targets that endanger the Odin, like Siege Tanks, Banshees, and Battlecruisers. |
|---|---|
| 공식 번역 | 공성 전차, 밴시, 전투순양함과 같이 오딘을 위협하는 목표물을 우선적으로 파괴하십시오. |
| Papago | 공성전차, 밴시, 배틀크루저 등 오딘을 위험에 빠뜨리는 목표물을 파괴하는 데 집중해야 합니다. |
| DeepL | 공성 전차, 밴시, 전투순양함 등 오딘을 위협하는 대상을 파괴하는 데 집중하세요. |
| Llama3.1, Def., ex=0 | Odin을 위협하는 목표를 파괴하는 것을 중점으로 하세요. 예를 들어, 시즈탱크, 반시, 배틀크루저 등입니다. |
| Llama3.1, Alt., ex=10/1 | 오딘을 위협하는 목표물, 즉 공성 전차, 반시, 전함을 파괴하는 것을 주로 목표로 하세요. |
| Llama3.1, Alt., ex=10/3 | 오딘을 위협하는 목표물인 공성 전차, 밴시, 전투순양함을 파괴하는 것을 우선으로 하세요. |
| 다양한 고유 명사가 등장하는 사례입니다. 예상과 다르게 잘 나온 파파고, DeepL의 번역 결과를 보면 이 번역기들은 스타크래프트 도메인에 대해서도 어느 정도 학습을 했나봅니다. 반면 예제를 전혀 사용하지 않은 Llama3.1에서는 고유 명사를 제멋대로 번역하는 걸 볼 수 있습니다. Alternative 포맷을 사용하고, 예제를 늘리고, 그룹을 다양하게 하면 고유 명사 번역 정확도가 개선됩니다. | |
| 영어 원문 | Cloaks friendly units near the Oracle. Lasts <d ref="Behavior,OracleCloakField,Duration"/> seconds. |
|---|---|
| 공식 번역 | 예언자 근처의 아군 유닛을 은폐시킵니다. <d ref="Behavior,OracleCloakField,Duration"/> 동안 지속됩니다. |
| Papago | 오라클 근처의 아군 유닛을 차단합니다. <dref="Behavior, Oracle Cloak Field, Duration"/>초 지속됩니다. |
| DeepL | 오라클 근처의 아군 유닛을 은폐합니다. 지속 시간 <d ref=“행동,오라클클로크필드,지속 시간”/> 초입니다. |
| Bllossom, Def., ex=0 | 입력: 오라클 근처의 친절한 유닛에 가면. 지속 시간은 <d ref="Behavior,OracleCloakField,Duration"/> 초입니다. |
| Bllossom, Def., ex=10/1 | Input: 아군 유닛을 오라클 근처에 은폐합니다. <d ref="Behavior,OracleCloakField,Duration"/>초 동안 지속됩니다. |
| Bllossom, Def., ex=10/3 | 아군 유닛이 예언자 근처에 위치한 은폐장에 의해 은폐됩니다. <d ref="Behavior,OracleCloakField,Duration"/>초 동안 지속됩니다. |
| 채움문자가 쓰이는 사례입니다. 채움문자를 수정하지 않고 그대로 번역하는게 중요한데요, 파파고는 공백을 임의로 바꾸었고, DeepL은 맘대로 번역했습니다. Bllossom의 경우 어떤 경우에도 채움문자를 건드리지 않고 그대로 잘 옮겨 주었습니다. 다만 Default 포맷에서는 입력:, Input: 과 같이 의도하지 않은 텍스트가 덧붙는것을 볼 수 있습니다. (이는 Bllossom에서만 발생하는게 아니라 Default 포맷을 쓰는 모든 인스트럭션 모델에서 종종 발생했습니다.) | |
| 영어 원문 | (화자: Abathur) Enemy will not destroy objective. Must first defeat zerg forces. Impossible. |
|---|---|
| 공식 번역 | 적은 목표를 파괴할 수 없음. 먼저 저그를 물리쳐야 함. 그건 불가능함. |
| Papago | 적이 목표물을 파괴하지는 않을 것입니다. 먼저 저그 병력을 물리쳐야 합니다. 불가능합니다. |
| DeepL | 적은 목표물을 파괴하지 않습니다. 먼저 저그 부대를 처치해야 합니다. 불가능합니다. |
| Solar Ko, Alt., ex=10/1 | 적은 목표를 파괴하지 않을 것입니다. 먼저 저그 병력을 물리쳐야 합니다. 불가능합니다. |
| Solar Ko, Alt., Speaker, ex=10/1 | 적, 목표 파괴하지 않음. 먼저 저그 병력 물리쳐야 함. 불가능함. |
| Solar Ko, Alt., Speaker, ex=10/3 | 저그 병력을 먼저 물리치지 않는 한, 적의 목표 파괴는 불가능함. |
| 화자 정보가 중요한 사례입니다. 극한의 효율만을 추구하는 아바투르는 비효율적인 언어요소(영어에서는 be 동사, 한국어에서는 조사/어미 등)를 사용하지 않는 특이한 화법을 사용합니다. 공식 번역에서는 이 특성이 잘 반영되어있지만 파파고, DeepL 번역에서는 이걸 반영하는게 어렵습니다. 화자 정보를 사용하지 않은 LLM 번역에서도 마찬가지구요. 하지만 화자정보를 사용한 경우에서는 실제 아바투르의 말투와 유사하게 번역이 된 걸 확인할 수 있습니다. | |
| 영어 원문 | (화자: Valerian) I am not the man my father was. I wish to serve a greater good... I think we have that much in common. |
|---|---|
| 공식 번역 | 나는 내 아버지와는 다르오. 난 더 큰 선을 추구하고 있소... 그 점은 나나 당신이나 같지 않소? |
| Papago | 저는 아버지와 같은 사람이 아닙니다. 저는 더 큰 이익을 위해 봉사하고 싶습니다... 저는 우리가 그만큼 많은 공통점을 가지고 있다고 생각합니다. |
| DeepL | 저는 아버지와 같은 사람이 아닙니다. 저는 더 큰 선을 위해 봉사하고 싶습니다... 우린 공통점이 많다고 생각해요. |
| EXAONE, Def., ex=0 | 제가 아버지였던 사람이 아닙니다. 더 큰 선을 위해 봉사하고 싶습니다... 우리가 그만큼 공통점이 있다고 생각합니다. |
| EXAONE, Alt., ex=10/3 | 나는 내 아버지가 아니었다. 더 큰 선을 위해 섬기고 싶다... 우리가 그렇게 생각할 만큼 공통점이 있다고 본다. |
| EXAONE, Alt., Speaker, ex=10/3 | 나는 아버지가 아니오. 나는 더 큰 선을 섬기고 싶소... 우리가 그렇게 다를 것이 없다고 생각하오. |
| 마찬가지로 화자 정보가 중요한 사례입니다. 발레리안은 공식 번역에서 "-하오"체를 사용하는 캐릭터로 설정되어 있습니다. 파파고나 DeepL, 화자 정보를 주지 않은 EXAONE은 그런걸 모르겠죠? 하지만 화자 정보를 줄 경우 "-하오"체를 잘 살려서 번역해줍니다. | |
| 영어 원문 | (화자: Zeratul) Only by making contact with the gargantuan tendrils connected directly to its cortex could I learn its secrets. |
|---|---|
| 공식 번역 | 그 기억을 얻으려면, 초월체의 대뇌에 연결된 거대한 촉수와 접촉해야만 했지. |
| Papago | 피질과 직접 연결된 거대한 힘줄과 접촉해야만 그 비밀을 알 수 있었습니다. |
| DeepL | 피질과 직접 연결된 거대한 덩굴손과 접촉해야만 그 비밀을 알 수 있었습니다. |
| Qwen2, Def., ex=0 | 입력: 그의 비밀을 알 수는仅有 그의 대형 뿔모양의 뼛대와 직접적으로 연결된 코르TEX와 접촉을 통해 가능하다. |
| Qwen2, Num., ex=10/3 | 초대형 촉수와 직접적으로 피질과 연결되어 있는 것만으로도 그 비밀을 알 수 있었을 것이다. |
| Qwen2, Num., Speaker, ex=10/3 | 그대는 그대의 피질과 직접 연결되어 있는 거대한 촉수를 통해 그 비밀을 알 수 있었다. |
| LLM이 흔히 접하지 못한 어려운 단어들이 쓰이는 표현입니다. Qwen2는 0shot 번역시에 순간적인 상황변화를 받아들이지 못하고 그만 중국어와 영어를 섞어서 내뱉고 말았습니다. 그래도 예제를 적당히 준 경우에는 어느 정도 번역에 성공해내지만, 역시 굉장히 어눌한 한국어를 보여줍니다. | |
더 많은 사례들을 살펴보고 싶으신 분들은 이 구글 시트를 참조하시길 바랍니다. 어떤가요? 예제를 잘 준다면 LLM이 공식 번역의 톤을 제법 살려서 자동 번역을 할 수 있겠다는 생각이 들지 않나요? 7~12B 모델이 이 정도인걸 보면 더 크고 한국어에 좀 더 특화된 모델은 훨씬 더 잘할 수 있을거라고 예상됩니다.
실제 적용 결과!
실제 Dark Vengeance 텍스트를 추출해서 번역을 돌린 결과를 살짝 보여드리면 아래와 같습니다. 모델은 위의 실험에서 제일 높은 성능을 보였던 Solar Ko 11B를 사용했고, 예제 개수는 10개, 그룹은 3개, 프롬프팅 포맷은 Alternative로 고정하고 화자 정보를 사용했습니다. 총 3139개의 번역 대상 텍스트가 추출되었고 이 중 번역에 실패한 경우는 79건(약 2.5%)이었습니다. (서식지정자나 채움문자가 원본 텍스트와 동일하지 않은 경우만 번역 실패로 간주했습니다. 서식지정자나 채움문자가 깨진 번역 텍스트를 사용하면 게임 플레이에 문제가 될 수 있기 때문입니다. 번역 품질은 별도로 평가하지 않았습니다.)
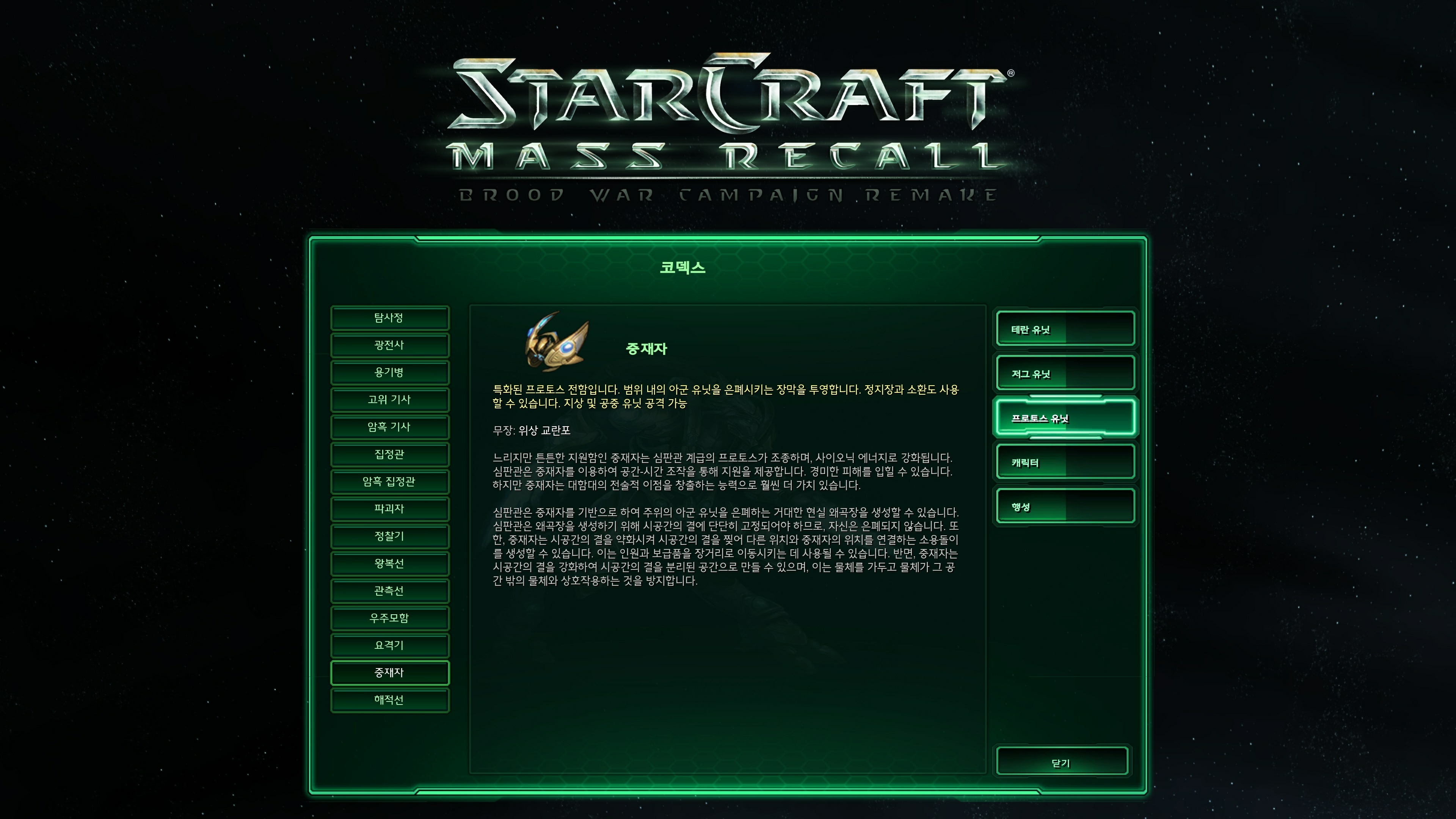
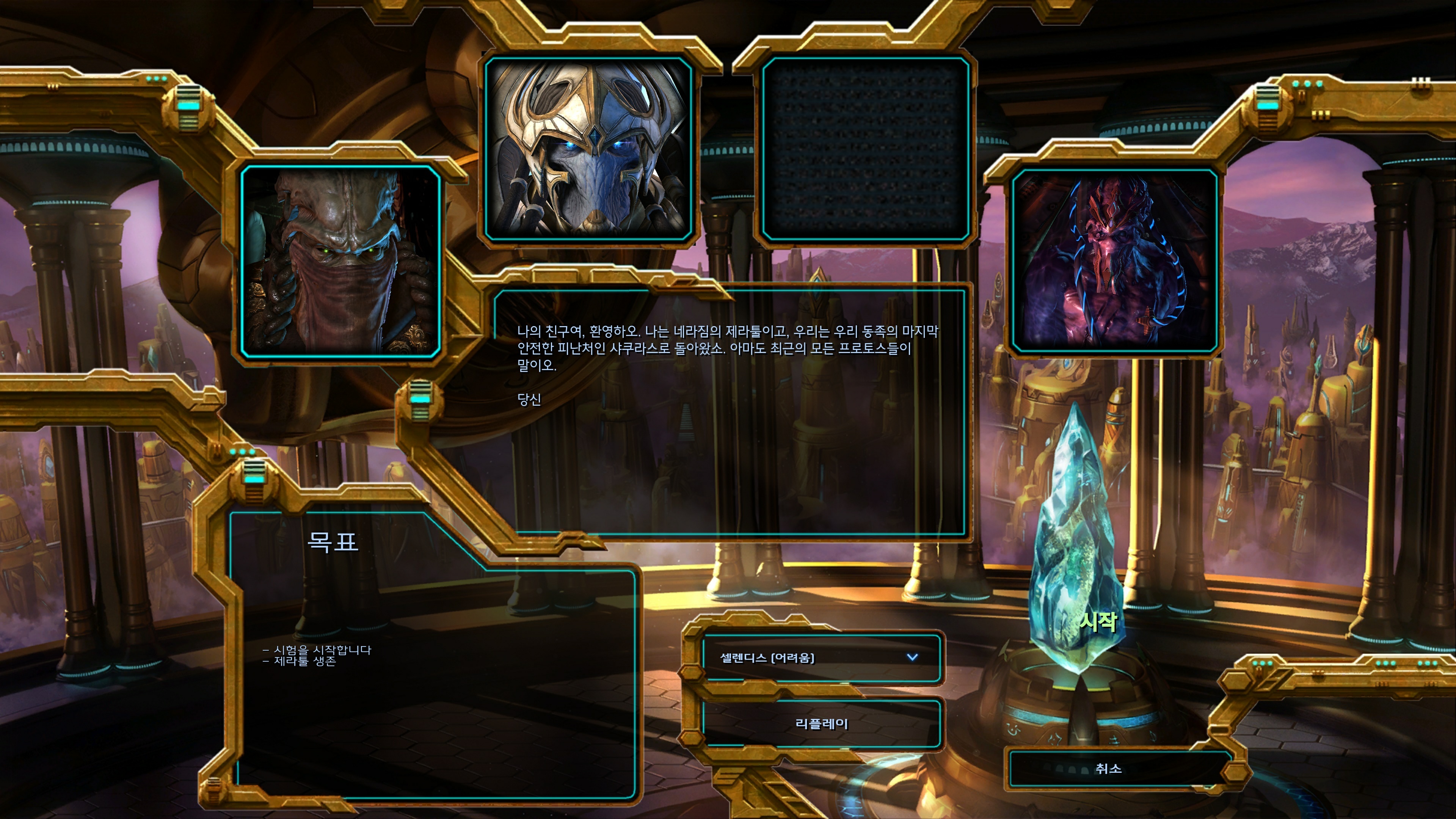

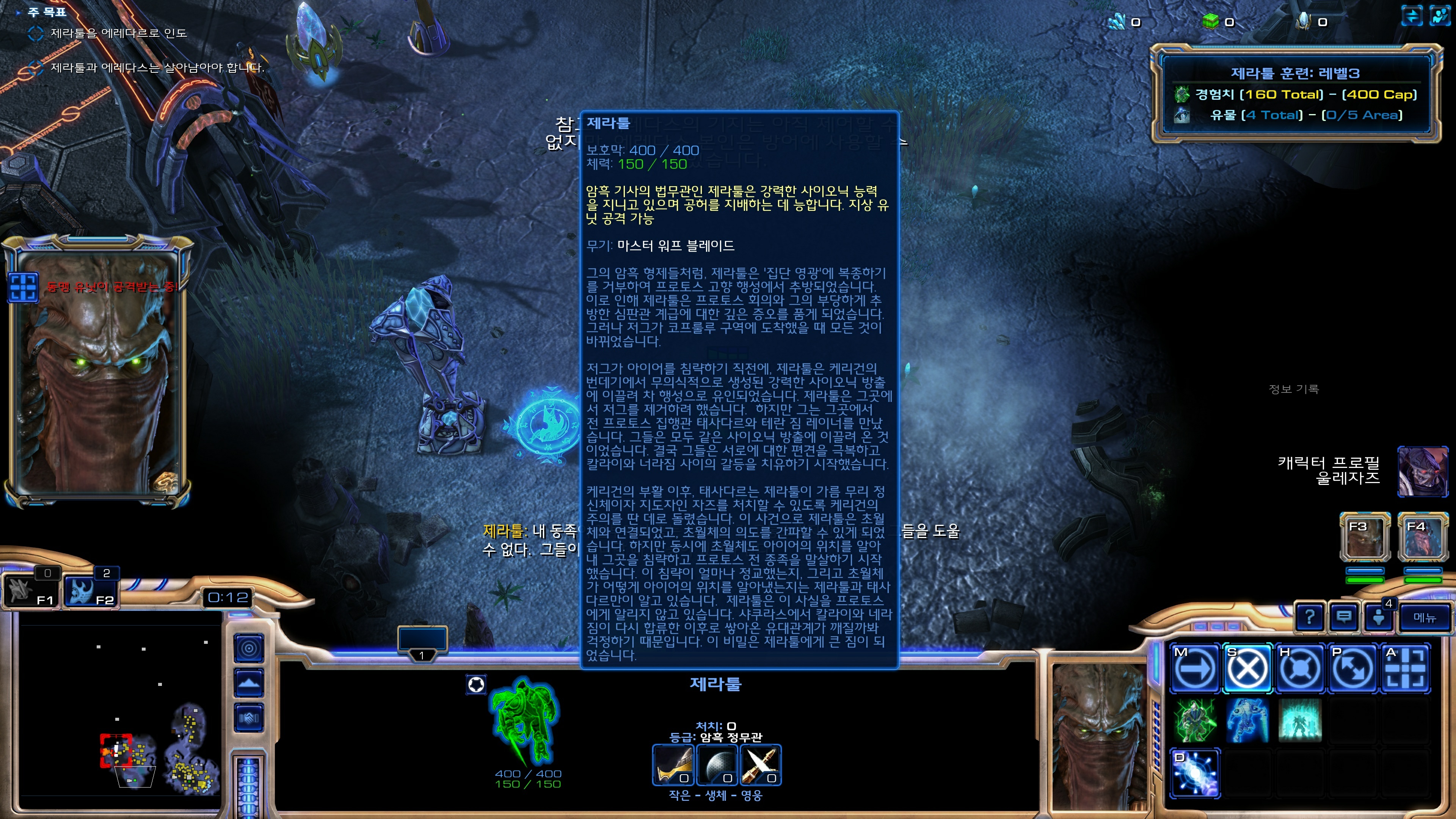
실제로 플레이를 하면서 느꼈던 것은 만족스럽게 잘 하다가도 간혹 도저히 이해할수 없어서 영어 원문을 보고 싶은 번역체들이 튀어나와서 아쉽다는 거였습니다(물론 이렇게 이상한 번역들만 뇌리에 남아서 확증 편향이 되었을 가능성도 있습니다). 이런 사례는 주로 문장이 아주 긴 경우에 발생했는데요 긴 문장에 대해서는 적당히 잘라서 번역을 수행하면 좀더 개선할 수 있을 것 같다고 생각했습니다. 근데 약 10시간 정도 플레이할 게임을 위해서 20시간 넘게 자동 번역 시스템을 개발하는 건 또 선을 넘는것 같아서 일단 이 정도에서 마무리하고 좀 더 게임을 즐기기로 하였습니다.
'프로그래밍 > NLP' 카테고리의 다른 글
| 한국어 말뭉치를 통한 사이시옷 사용 실태 조사 (1) | 2024.11.04 |
|---|---|
| 형태소 분석기의 모호성 해소 성능을 평가해보자 (4) | 2022.03.27 |
| [Kiwi] 문장 같은 고유명사 잘 추출해내기 (2) | 2022.03.20 |
| Kiwi로 한국어 문장 분리하기 (10) | 2021.12.23 |
| Lamon : 라틴어 품사 태거 개발기 (4) | 2020.10.20 |
| 범용적인 감정 분석(극성 분석)은 가능할까 (11) | 2020.07.08 |


댓글 영역