고정 헤더 영역
상세 컨텐츠
본문
사람의 언어를 이해하기 위해 컴퓨터가 하는 가장 기본적인 작업은 텍스트에서 단어를 인식하고 그 단어들의 특성을 파악하는 것입니다. 흔히 품사 태거(Part-of-speech Tagger, POS Tagger)라고 부르는 이 도구는 각 단어의 품사를 파악해주는 일을 수행합니다. 문법과 어휘는 언어별로 크게 상이하게 때문에 품사 태거는 각 언어에 맞춰서 개발되어야 하는데요 이 때문에 언어별로 다양한 태거들이 개발되어 왔습니다. 영어는 가장 먼저 품사 태거가 연구된 언어이고, 축적된 데이터와 기법들이 많아 현재는 95% 이상의 정확도(이 정도면 사람과 대등한 수준이라 볼 수 있습니다)로 품사 분석을 수행할 수 있습니다. 반면 한국어의 경우 단어가 단순히 띄어쓰기로 구분되지 않고 여러 형태소가 결합해 하나의 어절을 이루기 때문에 단어 분리와 품사 태거가 합쳐진 '형태소 분석기'를 개발해왔습니다. 형태소 분석은 단순 품사 태깅보다 복잡한 과제라 개발에 어려움이 있지만, 이 역시 데이터가 꾸준히 축적되고 여러 기법들이 도입되면서 높은 수준까지 올라온 상태입니다.
그러나 최근 제가 열심히 삽질 중인 라틴어의 경우 이미 사멸한 언어이고 전산화에 대한 관심도 적기 때문에 아직 제대로된 품사 태거가 개발되지 않았습니다. (만들어봐야 돈도 안되는걸 두 팔 걷어붙이고 뛰어들 사람이 있을리가 없죠.) 그래서 저는 몇 년전부터 다양한 경로를 통해서 라틴어 말뭉치는 많이 수집해 두었지만 이를 처리할 도구가 전무해 곤란한 상황입니다. 따라서 도구를 개발하는 작업부터 시작해야 했고, 2016년도에 아주 초보적인 형태의 태거를 개발했지만 절망적인 정확도로 반쯤 포기한 상태였습니다. 그러다 올해 초 새로운 아이디어가 떠올라 틈틈히 작업한 결과 Lamon이라는 이름의 새로운 라틴어 태거를 개발할 수 있었는데요, 이번 포스팅에서는 그 과정에 대해서 정리해보았습니다.
라틴어 '태거' 개발이 어려운 이유
품사 태거를 개발하는 방법에는 여럿이 있습니다만 요즘 유행하는(그리고 성능이 높은) 방법은 기계 학습을 이용한 것입니다. 품사 태깅이라는 문제는 결국 시퀀스 라벨링(Sequence Labeling)의 한 종류로 볼 수 있습니다. 시퀀스 라벨링은 다음과 같이 순서를 이뤄 들어오는 데이터 나열에 대해 하나씩 라벨을 붙여주는 작업을 말합니다.

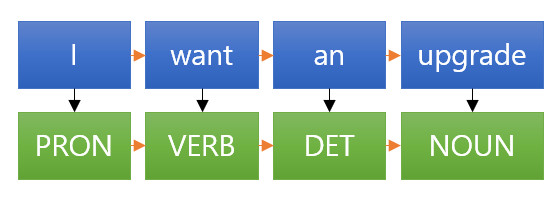
이 작업의 중요한 특징은 각각의 입력 데이터마다 출력 라벨이 붙지만, 이 라벨은 입력 데이터 하나에만 영향을 받는게 아니라 전체의 영향을 받는다는 것입니다. 영어에서 단어 upgrade가 어떤 맥락에서는 NOUN으로 쓰이지만, 또 다른 맥락에서는 VERB로 쓰일수 있는 것처럼 단어 하나만 보면 품사를 결정하기 모호한 경우가 많은데, 시퀀스 라벨링 기법을 적용하면 전후의 단어들을 바탕으로 적절한 품사를 추론하는 것이 가능해집니다.
기계학습을 통해서 이 모델을 학습하는 것은 의외로 간단합니다. 위처럼 입력 단어열과 출력 태그들을 쌍(=학습 데이터)을 매우 많이 준비하여, 컴퓨터가 특정 입력이 들어왔을때 어떤 출력을 생성해야하는지를 학습시키는 것입니다. (모델에 대한 구체적인 설명은 여백이 부족해 생략하겠습니다. 관심 있으신 분들은 HMM과 CRF에 대해 찾아보시길 추천드려요). 모델을 적절한 것으로 선택하고 충분히 많은 학습 데이터를 넣어준 경우 컴퓨터는 입력-출력 사이의 패턴을 찾아낼 수 있고, 이를 통해 학습 때 보지 못했던 문장이 들어와도 적절하게 품사 태그를 달아 줄 수가 있습니다.
그렇다면 품사 태거 개발이 어려운 이유도 짐작할 수 있습니다. 학습 데이터가 많~이 필요하기 때문이죠. 수 만 쌍은 있어야 실용적으로 쓸만한 정확도가 나오는데, 이를 구축하는건 굉장히 많은 시간과 예산(그리고 연구자)이 들어갑니다.

그래서 대안으로 학습 데이터 없이 스스로 학습을 수행하는 비지도학습(Unsupervised Learning)이 요즘 많이 관심을 받고 있습니다. 당연히 비지도학습은 학습데이터가 충분히 확보된 상황의 지도학습을 성능에서 앞지를 수 없지만, 학습 데이터가 부족한 상황에서는 비지도학습 외에는 선택지가 없을지도 모릅니다.
'라틴어' 태거 개발이 어려운 이유
사실 문제는 또 있습니다. 목표 언어가 라틴어이기 때문에 발생하는 문제인데요, 이 언어는 한 단어가 수 십~수 백 가지 형태로 굴절합니다(문법적 역할에 따라 단어의 모양이 달라집니다). 단어의 형태에 영향을 미치는 문법적 자질은 서법(mood), 시제(tense), 태(voice), 인칭(person), 성(gender), 수(number), 격(case), 급(degree)로 총 8가지입니다. 이들의 가능한 조합의 수는 어마어마하지요. 보통 명사는 10여가지, 형용사는 90여가지, 동사는 수 백 가지 정도됩니다.
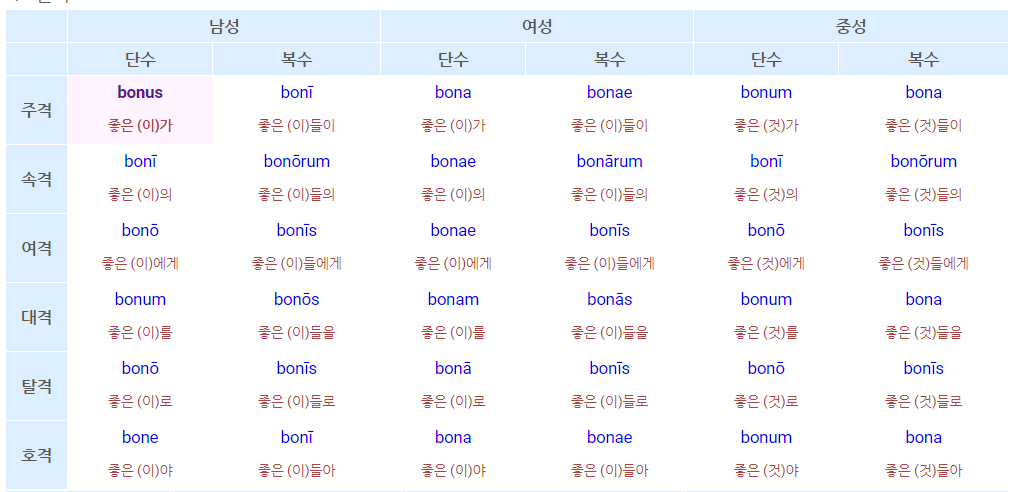
문제는 이 형태들이 다 다르면 좋겠지만, 겹치는 경우가 종종 있다는 것입니다. 위 표에 나온 형용사 bonus를 예로 들면 bona는 여성 단수 주격이 될수도 있지만, 중성 복수 대격이 될 수도 있습니다. 즉, 좋은 라틴어 태거라면 bona가 주어졌을때 이게 형용사라는 것뿐만 아니라, 여성 단수 주격인지, 중성 복수 대격인지 혹은 또 다른 조합인지 구분해줄 수 있어야합니다. 따라서 품사 태거가 할 일이 단순히 품사뿐만 아니라, 위의 8개의 자질을 맞추는 것으로 늘어났네요. 학습 데이터는 턱 없이 부족한데, 수행해야할 과제는 곱절로 어려워졌습니다. 이게 지난 몇 년간 라틴어 사이트를 운영하면서 맞닥뜨렸던 문제입니다.
쓸 수 있는 자원을 정리해보기
문제 해결에 앞서서 제가 사용할 수 있는 것들에 무엇이 있는지 정리해보았습니다.
- 각 단어별 변화형 목록
- 라벨링되지 않은 라틴어 문장 40만 개
- Perseus DL에서 구축한 라벨링된 라틴어 문장 4000개
- 내가 가끔씩 라벨링해둔 라틴어 문장 900개
1번의 경우 웹사이트용 사전을 개발하면서 라틴어 단어별 변화형을 패턴별로 모아두었습니다. 변화형이 많아서 무지막지해보일지도 모르지만, 사실은 대부분의 규칙에 의해 변화하기 때문에 규칙만 숙지하면 대부분의 변화를 규칙에 의해 설명할 수 있습니다. (그런데 규칙을 숙지하는게 어려운게 문제..) 따라서 1번을 이용해 어떤 형태의 단어가 주어지면, 이 단어가 어떤 사전 원형(lemma)의 변화형태인지 나열해볼 수 있습니다. 예를 들어 bona가 주어지면 이게 bonus의 여성 단수 주격이거나 bonus의 중성 단수 대격이라고 알 수 있는 식이지요. 이를 통해 임의의 단어가 주어졌을때 품사와 8개의 자질을 맞추는 문제는 주관식에서 객관식으로 바뀌었습니다. 규칙에 기반해 주어지는 후보목록 중 정답 하나만을 선택하는 되는 거지요. (그러나 사전에 등재되지 않은 단어나 고유 명사 등에 대해서는 여전히 주관식으로 문제를 풀어야합니다.)
라벨링된 문장의 숫자는 다 합쳐도 5000건이 채 안됩니다. 이를 통해 지도학습을 수행하는 건 사실상 어려우므로 준지도 학습(semi-supervised learning)으로 문제를 접근하기로 결정했습니다. 직접 라벨링한 문장 900개는 성능 평가용으로 따로 빼두고, 4000건만 학습에 참여시키도록 했습니다.
관건은 2번, 라벨링되지 않은 대량의 말뭉치1를 어떻게 사용할 것인지입니다. 자연어처리 기법에서는 이렇게 말뭉치만 주어진 경우 Word2Vec이나 GloVe 혹은 최신 유행하는 BERT 등 미리 학습된 임베딩(pretrained embedding)을 통해 언어에 내재된 특성들을 뽑아내어 사용하는 경우가 많습니다. 비유를 하자면, 영어를 가지고 작업을 할거긴 한데 어떤 작업을 할지는 모르는 상태라서, 일단 영어 전반에 대해 공부를 해두고 있는 셈입니다. 이렇게 미리 영어를 공부해둔 사람이라면 영어를 가지고 분류를 하는 문제나 라벨링을 하는 문제 등을 주면 영어를 전혀 공부해두지 않은 사람보다 더 잘할수 있을테지요. 이렇듯 미리 학습된 임베딩은 주어진 대량의 말뭉치에서 특정 단어와 주로 같이 출현하는 단어들에는 어떤것이 있는지, 혹은 특정 맥락에서는 어떤 단어가 주로 출현하는지 등을 파악함으로써 각 단어의 의미를 스스로 파악하고자 합니다.
그럼 2번 데이터를 가지고 라틴어 버전 미리 학습된 임베딩을 학습시키면 좋겠네요! 그런데 여기에는 장애물 하나가 있습니다. 앞서 설명했다시피 라틴어는 한 단어가 수 십에서 수 백 가지 형태로 변화하기 때문에 전체 말뭉치 내에 포함되는 서로 다른 단어 형태의 수는 수십만 가지가 됩니다. 그런데 실제 쓰이는 단어 원형을 찾아보면 1~2만개에 그칩니다. 1~2만개의 단어가 수십만 가지로 나뉘어 쓰이다 보니 동일 단어가 여러 다른 단어로 인식되지요. 그 결과 컴퓨터가 단어의 의미를 파악하는데 어려워하게 됩니다. 2 그래서 이를 사전 원형으로 변환해준다음 학습을 진행해야하는데, 그러려면 라틴어 품사 태거가 필요합니다.
품사 태거를 개발하려고 미리 학습된 임베딩을 학습하려하는데, 이걸 하려면 품사 태거가 필요하다..? 이 방법은 쓰기 어려워 보이네요.3
언어 모델을 자기 학습시키기
그래서 고안한 방법은 언어 모델(Language Model)을 자기 학습(Self Training)시키는 것입니다. 언어 모델은 특정 맥락이 주어졌을 때 다음에 나타날 단어를 맞추는 확률 모델을 가리킵니다. 이를 테면 다음과 같은 문장이 주어진다면
나는 사과를 ___ .
빈 칸에 먹는다 혹은 받는다 등이 나올 확률이 높은 반면, 뛰었다, 공부한다 등이 나올 확률이 낮다는 것을 계산할 수 있는 모델인 것입니다. 보통 언어 모델을 학습시키기 위해서 대량의 말뭉치를 학습하면서 특정 단어열 다음에 어떤 단어가 등장하는지는 통계적으로 학습합니다. (A-B-C가 나왔을때 뒤에 D가 나온 비율을 따지는거라 생각하면 쉽습니다.)
만약 사전원형(lemma)과 위에서 언급한 품사와 8개의 자질(feature)의 조합을 입력으로 받는 언어 모델을 학습시키면 특정한 (lemma, feature) 배열 이후에 어떤 (lemma, feature) 조합이 나올 확률이 높은지 알 수가 있겠지요.
audiat terra verba oris mei.

위의 표는 각 형태가 어떤 (lemma, feature) 조합이 될 수 있는지 나열한 것입니다. 예를 들어 audiat은 (audio, 접속법 현재 능동 3인칭 단수) 1가지 후보 밖에 없습니다. 반면 mei는 (ego, 단수 속격)이나 (meus, 남성 복수 주격) 등 총 5가지 후보 중 하나가 될 수 있지요. 앞서 말한 (lemma, feature) 언어 모델이 잘 학습되어 있다면, 먼저 첫번째 단어를 (audio, 접속법 현재 능동 3인칭 단수)로 입력했을때, (terra, 여상 단수 주격), (terra, 여상 단수 탈격), (terra, 여상 단수 호격) 중 다음 단어로 나올 확률이 높은게 무엇인지 알아낼 수 있겠지요. 이렇게 다음 단어의 (lemma, feature) 조합이 (terra, 여성 단수 주격)임을 알아냈다면 이제는 [(audio, 접속법 현재 능동 3인칭 단수), (terra, 여성 단수 주격)]를 모델에 넣고 다음단어로 verba의 어떤 조합이 나올 건지를 따질 수 있습니다. 이런식으로 끝까지 진행하여 가장 확률이 높은 경로를 찾아낸다면 언어 모델은 'audiat terra verba oris mei'의 lemma와 feature를 모두 성공적으로 발견해낼 수 있을겁니다. 좋지요?
그런데 이 언어 모델을 어떻게 학습시킬까요? 결국 이 모델을 학습시키려면 (lemma, feature)가 이미 밝혀진 문장들이 많이 있어야할텐데요. 이를 회피하기 위해 자기 학습(Self training)4을 사용하기로 했습니다. 학습 절차는 다음과 같습니다.
- 처음에는 규칙 기반으로 얻어진 (lemma, feature) 후보 중 아무거나 선택하여 정답으로 간주한다.
- 1번의 정답을 가지고 언어 모델을 학습한다.
- 학습이 어느 정도 진행되면 지금까지 학습된 모델로 임의의 문장의 (lemma, feature)을 예측하고 이 것을 정답으로 간주한다.
- 3번의 정답을 가지고 언어 모델을 학습한다.
- 모델이 수렴할때까지 3번으로 돌아가 반복한다.
- 충분히 학습을 진행하여 수렴되면 Profit!
3~4번 과정을 보면 자신이 예측한 결과를 가지고 학습을 진행하기 때문에 '자기 학습'이라는 이름이 붙었습니다. 어이없는 방법이긴 한데, 생각보다 잘 작동합니다. 왜 그럴까요?

수식으로 설명하려면 어렵겠지만, 사람들이 미해독 암호나 오래된 문자들을 해독하는 걸 상상해보면 그 과정이 쉽게 이해될 수 있습니다. 위 그림은 원시 그리스어를 적는데 사용된 선문자B라는 문자인데 알려진 어떤 문자와도 상관이 없는 문자입니다. 전혀 알려진 게 없는 문자였음에도 학자들은 1950년대에 이를 해독하는데에 성공하여 그리스어를 적는데 사용된 것이라고 알아낼 수 있었습니다. 학자들이 이걸 풀기 위해 먼저 문자들이 등장하는 패턴을 파악하고, 각 문자가 어떤 의미(혹은 소리)를 지닐지 가설을 세워봅니다. 이 가설을 바탕으로 다른 문자열에 대해서 해독을 실시하여 그럴싸한 뜻이 나오는지를 확인해봅니다. 다른 문자열에서 뒤죽박죽인 결과가 나오면 그 가설은 폐기하고, 또 새로운 가설을 세웁니다. 여러 가지 가설들을 시험해보다보면 언젠가 다른 문자열에 대해서도 제법 그럴싸한 해석이 나오는 조합을 찾을 수 있을겁니다. 그럼 다른 문자열에서 나온 결과를 바탕으로 가설을 수정/보완하고 또 다른 문자열에 대해서 검증을 반복합니다. 최종적으로 최대한 많은 문자열들에 대해 그럴싸한 결과를 내는 조합을 발견하면 이를 해독했다고 이야기할 수 있습니다. 이렇게 정답을 전혀 모르는 상태에서 문자 표본만 잔뜩 있는 상황에서 이를 해석하는게 가능했던 것은 저 선문자 B로 작성된 글들을 많이 발견했기 때문입니다. (위키백과에 따르면 3만개 이상의 표본을 발견했다고 하네요.) 만약 발견된 표본이 너무 적었다면 이런 가설과 검증의 과정이 불가능했을겁니다.
위의 자기 학습도 비슷하게 생각해볼 수 있습니다. 1번은 가설을 세우는 단계와 유사합니다. 이 때 정답을 랜덤으로 선택하기 때문에 학습 데이터에 아예 엉뚱한 조합이 들어가 있을수도 있고, 실제 정답에 가까운 조합이 들어가 있을 수도 있습니다. 언어 모델은 주어진 맥락을 가지고 다음 단어를 예측하는 일을 하기 때문에 입력 맥락과 출력 단어의 패턴화가 가능하면 잘 학습할 수 있습니다만, 패턴화가 불가능한 경우는 학습을 잘 하지 못합니다. 즉, 패턴화 가능한 데이터와 노이즈 중에서 모델이 학습하기 쉬운 것은 패턴화 가능한 데이터라는 것이지요. 따라서 1번 단계에서 아무 가설이나 막 던져주어도, 노이즈를 학습하지 못하는 모델 때문에 자연히 일부 가설들은 무시(정확히는 한 노이즈가 다른 노이즈와 상쇄됨)됩니다. 즉, 2번 단계는 가설을 검증하는 단계와 유사합니다. 3~4번은 1~2번 과정과 동일합니다만, 모델이 세우는 가설이 1~2번에 비해 더 정교해졌다는 차이가 있습니다.
이를 수학적으로 풀어쓰면 다음과 같이 되겠습니다. $w$는 관측되는 실제 단어들, $\lambda$은 지금은 잘 모르지만 알고 싶은 각 단어들의 (lemma, feature) 조합 (잠재 변수). $Dec(\lambda|w)$은 단어 w가 (lemma, feature) 조합 $\lambda$로 해석될 확률, $LM (\lambda_i|\lambda_0 \cdots \lambda_{i-1};\Theta)$ 는 잠재변수 $\lambda_0$ ~ $\lambda_{i-1}$이 주어졌을때 현재 언어모델 파라미터에 의해 다음 단어 $\lambda_i$가 예측될 확률을 가리킵니다.
$$\prod_{W} { LM(\lambda_i|\lambda_0 \cdots \lambda_{i-1};\Theta) Dec(\lambda_i|w_i) }$$
모든 문장들 $W$에 대해 이 확률의 조합을 최대한 크게하는 $\lambda$과 $\Theta$를 찾는게 학습의 목표가 될 것이구요. 실제로 모든 가설을 테스트해보려면 가능한 모든 $\lambda$의 조합을 다 따져보아야 하겠지만, 학습에 사용하는 문장이 한 둘이 아니므로 가능한 조합은 몇 조 가지 이상이 나올지도 모릅니다. 그래서 일단 랜덤으로 $\lambda$을 부여하고 $\lambda$과 $\Theta$를 조금씩 바꿔가면서 전체 확률이 커지는 방향으로 모델을 개선하는 것이지요.
lemma - feature 조합의 장점
라틴어 모델을 위해 lemma와 feature를 조합하여 사용하는 것은 여러 면에서 이점이 있습니다. 먼저 8가지 문법 자질은 대체로 서로가 서로에게 영향을 미치지 않는 편입니다. 예를 들어 격(case)은 이 단어가 주어로 쓰이는지, 목적어로 쓰이는지 등에 따라 결정되는 반면, 성(gender)은 명사가 가리키는 문법 성에만 영향을 받습니다. 위에서 나왔던 형용사 bonus를 다시 예로 들어보자면, bona는 여성 단수 주격 / 여성 단수 탈격 / 중성 복수 주격 / 중성 복수 대격 등이 될 수 있습니다. 만약 주어진 맥락이 '대격'(목적어)을 필요로 하는 상황이라면 우리는 높은 확률로 bona는 '중성 복수 대격'이라고 추론할 수 있습니다. 반대로 주어진 맥락에서는 '여성'이 필요하다면 우리는 bona가 '여성 단수 주격'이거나 '여성 단수 탈격'이라고 후보를 좁힐 수 있겠지요.
또 oris는 여성 명사인 ora(경계)의 '복수 탈격형'일수도 있고, 중성 명사인 os(입)의 '단수 속격형'일수도 있습니다. 만약 주어진 맥락이 단수를 요구한다면 중성 명사인 os가 올바른 lemma일거라고 추론이 가능하고, 탈격을 요구한다면 ora가 올바른 lemma일거라 추론이 가능하지요. 거꾸로 '입'이라는 뜻이 필요한 맥락인지 '경계'라는 뜻이 필요한 맥락인지를 이용해 feature를 더 정교하게 추론하는 것도 가능하구요. 이렇듯 lemma와 feature를 조합함으로써 모호할 수 있는 선택지를 크게 좁힐 수 있습니다.
각 단어에 대해서는 lemma와 feature를 조합하여 후보를 추리지만, 실제 언어 모델에서는 lemma와 feature를 각각 별도로 학습합니다. 즉, lemma를 정확하게 한정할 수 있지만 feature에 대해서는 모호한 데이터를 학습할때는, 확실한 lemma는 더 강하게 학습하고 모호한 feature는 약하게 학습하는 게 가능하지요. (반대도 마찬가지입니다). 이를 통해 수많은 문장 조합에서 강하게 예측 가능한 lemma, feature를 찾아 학습함으로써 조금 모호한 부분도 더 정확하게 추론 가능해지고, 조금 모호한 부분을 비교적 더 정확하게 추론해 학습함으로써, 더 모호한 부분도 조금씩 명확하게 한정해 나가는 셈입니다. 아무것도 모르던 인류가 확실하게 아는 것들 몇개를 바탕으로 조금씩 지식을 밝혀나가는 것과 비슷해보이지 않나요? 그런 점에서 개인적으로 상당히 재미있어하는 학습 기법입니다.
좀 더 기술적인 내용
이 단락에서는 좀 더 기술적인 내용에 대해서 소개합니다. 먼저 언어 모델로는 단순 BiLSTM을 사용했습니다. Attention이 포함된 모델이나 최신 유행하고 있는 Transformer 기반의 GPT 모델도 사용해봄직하지만, 자기 학습을 위해서는 모델 학습 과정에서 학습 뿐만 아니라 끊임없이 추론도 함께 수행해야하므로 무거운 모델을 최대한 배제하기로 했기 때문입니다. 또한 크고 무거운 모델을 학습시킬만큼 데이터 양이 많지 않기도 했구요. Lemma와 Feature는 벡터로 임베딩하여 더한 뒤 BiLSTM 셀의 입력으로 들어갑니다. LSTM셀은 입력된 (Lemma, Feature) 조합의 다음에 나올 (Lemma, Feature) 조합을 예측합니다. (정확하게는 Forward LSTM에는 다음 단어를 예측, Backward LSTM에서는 이전 단어를 예측하겠지요.) 두 LSTM에서 생성된 결과는 Dense 레이어를 통과해 Lemma와 Feature 결과를 만드는데에 사용됩니다.
 |
 |
Lemma와 Feature를 예측하는 방법으로는 두 가지가 떠올랐습니다. 첫번째는 BiLSTM의 출력에서 Lemma와 Feature를 각각 예측하는 방법입니다(왼쪽 그림). 이 경우 Lemma와 Feature가 독립적으로 예측됩니다만, 규칙에 의해 불가능한 (Lemma, Feature) 조합은 제거될 수 있으므로, 엉뚱한 (Lemma, Feature) 조합이 생성될 염려는 하지 않아도 됩니다. 두번째는 BiLSTM의 출력에서 먼저 Lemma를 예측한 뒤 예측된 Lemma의 임베딩 값을 다시 가져와 BiLSTM의 결과와 결합하여 Feature를 예측하는 방법입니다(오른쪽 그림). Lemma에 맞춰 Feature를 예측하므로 첫번째 방법보다 좀더 정확하게 예측이 가능하겠지만, 연산이 복잡합니다. 간단한 첫번째 방법을 먼저 구현하여 0.1.0버전으로 실험하였고, 이후 좀 더 복잡한 두번째 방법을 구현하여 0.2.0버전에 사용했습니다.
Lemma와 Feature의 임베딩 크기는 160, LSTM 셀의 은닉층 크기는 320으로 설정했고, Forward, Backward 셀의 결과를 모아서 통과시킨 Dense층의 크기는 640으로 잡았습니다. 최적화는 Adam을 사용했고, 총 20000 step 동안 학습을 진행했습니다. 학습 시에는 0.1의 확률로 dropout을 적용하여 모델이 과적합되는 것을 방지하는 것도 빼먹지 않았구요.
앞서 설명한 바와 같이 자기 학습을 위해서 조금 학습된 모델로 새 데이터를 예측해 학습 대상으로 삼는 작업이 필요했는데요, 무작위 정답 선택에서 모델에 의한 선택으로 자연스럽게 넘어갈 수 있도록 담금질 기법을 적용했습니다. 위의 왼쪽모델의 예측 부분을 수식으로 풀어쓰면 다음과 같습니다. LSTM의 출력 결과를 $O$라고 하면 Lemma 예측 결과는 Lemma projection 행렬 $W^l$에 $O$를 곱한 것으로 구할 수 있고, 여기에 softmax를 취하면 확률 분포가 됩니다. Feature 예측 결과도 마찬가지로 Feature projection 행렬 $W^f$에 $O$를 곱하고 softmax를 취하면 되지요. 따라서 해당 맥락에서 (l, f)라는 (Lemma, Feature) 조합이 나올 확률은 아래와 같이 쓸 수 있습니다.
$$ P(l, f | O) = softmax\left(W^l \: O\right)_l \cdot softmax\left(W^f \: O \right)_f $$
그러나 위의 수식대로 계산된 (l, f)의 등장확률은 모델이 잘 학습된 경우에만 쓸만할 것입니다. 학습이 전혀 안된 모델에 대해서는 위 식을 그대로 계산하면 오히려 그릇된 결과를 얻을 수도 있으므로, 초기에는 아무거나 고르는게 낫습니다. 아무거나 고른다는 말은 어떤 (l, f) 조합도 동일한 확률로 선택되게 한다는 것이지요. 이를 위해서 temperature 변수 $\tau$를 도입합니다.
$$ P(l, f | O) = softmax\left(\tau \: W^l \: O\right)_l \cdot softmax\left(\tau \: W^f \: O \right)_f $$
학습 처음에는 $\tau = 0$으로 시작합니다. 이 경우 $W^l \: O$ 가 어떤 값을 내던 간에 0이 되어버리므로, softmax를 통과하고 나면 모든 조합이 동일한 확률을 가지게 됩니다. 그러나 학습이 조금씩 진행됨에 따라 $\tau$를 점차 증가시켜가며 최종적으로는 1이 되게 합니다. 그럼 나중에는 아무 간섭 없이 모델이 예측하는 결과를 그대로 가져다가 다시 학습에 사용하는 셈이 됩니다.
BiLSTM을 사용했으므로 학습 결과 디코딩도 양방향을 고려하는 Beam Search를 사용해야 하겠지만, 학습 도중 GPU로 BiBeamSearch를 구현하는 것은 너무 느리므로, 그냥 Forward 방향으로 샘플링한 결과 절반, Backward 방향으로 샘플링한 결과 절반을 합쳐서 모델이 다시 학습하도록 했습니다.
또한 완전 비지도학습으로 모델을 학습시킬 경우 스스로 패턴을 발견하긴 하지만, 그 패턴이 사람이 생각하는 정답과 동떨어진 결과가 될 수도 있습니다. 이를 방지하기 위해 Perseus DL에서 구축한 라벨링된 라틴어 4000문장을 추가 학습데이터로 사용했습니다. 지도 학습을 진행하는 중간 중간, 정답이 밝혀진 데이터를 넣어 학습시켜줌으로써 모델이 잘못된 패턴을 정답으로 착각하여 오답의 구렁텅이에 빠지는 일을 방지한 것입니다.
모델 학습 결과
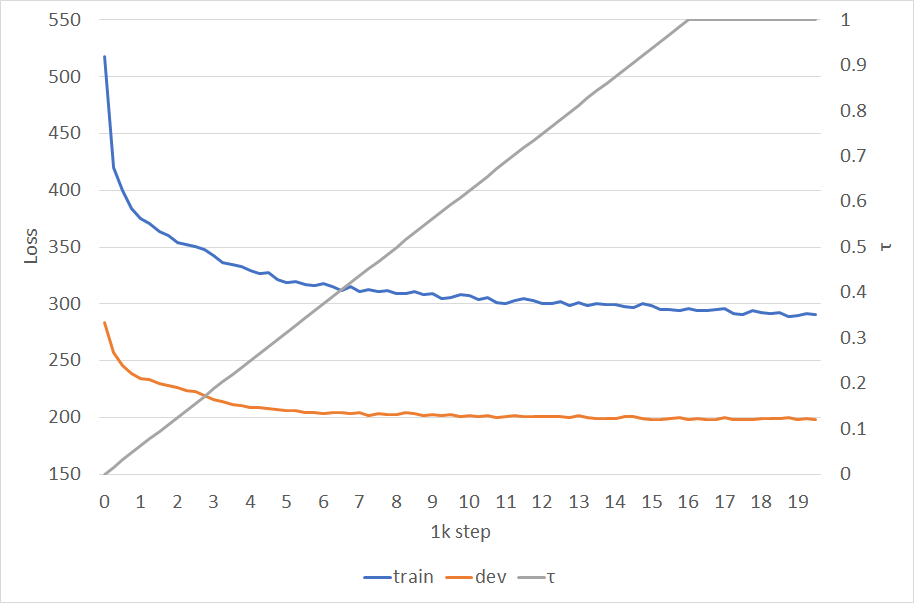
위의 그래프를 보면 $\tau$를 서서히 증가시킴에 따라 train loss와 dev loss가 안정적으로 감소하는 것을 확인할 수 있습니다. $\tau$를 너무 빨리 증가시키면 모델이 엉뚱한 결과를 배워버려 loss가 수렴하지 못하고, $\tau = 0$으로 고정하면 loss가 최적값에 도달하지 못합니다. 학습이 잘 진행된 것 같으니 900문장의 평가 데이터를 이용해서 성능 평가를 진행해보았습니다.
양적 평가
비교 대상으로 삼을 만한 품사 태거를 여기 저기 수소문한 끝에 CLTK에서 개발한 POS Tagger가 있다는 것을 알아냈습니다. 위에서 소개한 Perseus DL의 라벨링 데이터를 이용해 학습했다고 하네요. 그런데 아쉽게도 lemma와 feature 쌍을 한꺼번에 추론해주는 기능은 없고 lemma를 추론해주는 기능과 feature를 추론해주는 기능이 따로 있습니다. 그 말은즉슨 feature를 추론할때는 lemma를 고려하지 않고, lemma를 추론할때는 feature를 고려하지 않는다는 것이죠. 그래서 명사인 단어에 시제나 서법을 붙이거나, 동사에 성별을 붙이는 등 잘못된 결과를 내는 경우가 많습니다. 그래도 일단 비교대상이 있다는게 어딥니까~ CLTK의 라틴어 태거와 이번에 새로 개발한 Lamon, 그리고 2016년에 주먹구구식으로 만든 태거(=옛날 태거)에 대해 lemma를 맞춘 경우, feature를 맞춘 경우, 둘 다 맞춘 경우를 평가하여 정리해보았습니다.
| Lemma | Feature | Both | |
|---|---|---|---|
| 베이스라인 | 87.8 | 66.8 | 64.1 |
| 옛날 태거 | 92.9 | 79.0 | 77.5 |
| Lamon v0.1.0 | 94.3 | 83.7 | 81.7 |
| Lamon v0.1.0 (uv.) | 94.3 | 82.6 | 80.7 |
| Lamon v0.2.0 | 95.0 | 84.9 | 83.2 |
| CLTK(123)* | 88.0 | 58.4 | 54.9 |
| CLTK(CRF)* | 88.0 | 69.1 | 63.4 |
(*CLTK의 123, crf 태거는 모두 feature만 예측해주는 태거라서, lemma 결과에는 backoff lemmatizer로 lemma를 예측한 결과를 대신 넣었음)
베이스라인은 규칙과 표로 걸러낸 (Lemma, Feature) 후보 들 중 아무거나 무작위로 선택했을때의 결과를 보여줍니다. lemma의 경우 막 찍어도 87%는 맞출수 있군요. 반면 feature는 8개 자질의 조합을 정확히 맞춰야하므로 조금 더 어려워서 무작위로 선택시 66% 정도만 맞출 수 있습니다. 최종적으로 둘 다 맞추는 경우는 64%에 불과합니다. 생각보다 베이스라인이 높은 이유는 라틴어에서 자주 쓰이는 전치사 등 일부 단어들은 전혀 변화하지 않고, 한 가지 형태만 가지기 때문에 틀릴려야 틀릴 수 없습니다. 이런 단어들 덕분에 무작위로 선택해도 최소 64% 정확도는 보장이 되는 것입니다. 그래서 위의 표를 해석할 때 64%는 0점이라고 이해하시는게 좋습니다.
CLTK의 태거들은 사실상 0점보다도 더 낮은 점수를 기록했습니다. 이는 앞서 설명한대로 lemma를 무시하고 feature만 예측하기에 특정 단어가 가질 수 없는 feature 조합을 생성해내는 문제가 있기 때문입니다. 보기에 없는 답을 고른 셈이죠.
Lamon의 결과는 고무적입니다. 예상대로 lemma의 결과를 바탕으로 feature를 예측하는 0.2.0버전이 더 높은 정확도를 보였으며, lemma에 대해서는 약 95%, feature에 대해서는 약 85%의 정확도로 올바른 태그를 붙여주었습니다. 0.1.0버전에 대해서는 Perseus DL 데이터를 추가 학습데이터로 쓴 모델(Lamon v0.1.0)과 학습 데이터를 전혀 쓰지 않은 모델(Lamon v0.1.0 (uv.))의 결과를 모두 표기했는데요, 이를 보시면 학습 데이터를 썼음에도 성능향상은 약 1%p에 그쳤다는 걸 알 수 있습니다. 즉 Lamon의 성능은 지도학습 데이터로부터 온 것이 아니라 대부분 자기 학습으로부터 왔다는 것을 알 수 있습니다.
질적 평가
수치는 충분히 보았으니, 실제 Lamon이 어떤 결과들을 내는지 확인해봅시다. Lamon으로 분석된 말뭉치에서 헷갈릴법한 단어들을 뽑아보았습니다. 이를 통해 lemma를 정확하게 라벨링했는지만 알 수 있고 feature의 정확도에 대해서는 알 수 없지만, 각 문장들을 문법적으로 분석해보지 않아도 되므로 예시로 들기에 쉬워서 선택하였습니다.


먼저 sine라는 형태를 공유하는 전치사 sine(~없이)와 동사 sino(허락하다)입니다. 전치사 sine는 항상 뒤에 탈격을 데리고 다니는 특징이 있는데, 모델이 이를 잘 파악한 것 같습니다. 반면 동사 sine는 뒤에 탈격이 따라오지 않습니다. 전치사 sine로 분류된 4번째 예시는 사실 동사 sino인데 모델이 잘못 분류한 경우입니다. 이는 sine뒤의 me가 탈격으로 보이기도 하기 때문입니다. (이 경우 해석은 '나 없이'가 되지요.) 이 때문에 모델이 혼동을 일으켰나봅니다.


다음은 os라는 형태를 공유하는 두 명사 os입니다. 둘다 주격에서는 os라는 형태지만 '입'을 뜻하는 os는 oris, ori 등으로 변화하고 '뼈'를 뜻하는 os는 ossis, ossi 등으로 변화합니다. 따라서 모델이 oris나 ossis 등의 분포를 통해서 각 단어의 의미를 대략적으로 파악하여, os가 등장할 때 '입'의 맥락에서 쓰였는지 '뼈'의 맥락에서 쓰였는지 구분할 수 있게 됩니다. 이론은 완벽했지만, 뼈로 분류된 os중 1,4번은 잘못 분류되었네요.


liber라는 형태를 공유하는 명사 liber(책)과 형용사 liber(자유로운)입니다. 명사 liber의 4번째 사례를 제외하고는 정확하게 분류했습니다.


parere라는 형태를 공유하는 동사 pareo(순종하다)와 pario(출산하다)입니다. 보다시피 출산하다는 의미의 parere들을 pareo로 잘못 분류한 경우가 많습니다. 반면 pario로 제대로 분류한 사례는 1건밖에 없구요. pareo와 pario가 공유하는 형태들이 많다보니 모델이 둘의 차이를 학습하는데에 실패한 것으로 보입니다.
사실 겹치는 형태가 존재하는 lemma를 정확하게 구분하는 문제는 단어 중의성 해소(Word Sense Disambiguation)으로 직결되는 문제인데요, Lamon이 WSD 관련 학습을 수행하지 않았음에도 어느 정도 이를 수행해내고 있다는 점이 놀랍습니다. 물론 아직 실용적으로 쓰기에는 많이 부족한 성능이긴 하지만요.
저에겐 느린 CPU서버 밖에 없어요~
일단 성능이 나쁘지 않게 나왔으니 웹 사이트에 적용하려고 하는데, 문제는 저에게 GPU 서버가 없다는 겁니다. 모델 개발은 tensorflow-gpu를 이용해서 했는데 (호스팅할 돈도 없고 생각도 없구요..)... 사실 RNN계열 모델 디코딩은 GPU에서 크게 빠르게 돌아가는 작업이 아닙니다. 이전 단어가 바로 다음 단어에 영향을 주는 구조이기 때문에 병렬화가 어렵습니다. 게다가 입력이 batch로 들어오는게 아니라, 한 문장씩 따로 들어오는거라면 오히려 GPU와 통신하는 비용이 더 커져서 안 쓰느니만 못한 결과가 나옵니다. 그래서 결론은 CPU에서 돌아가게 C++로 작업해야한다는 것입니다.
구현에서 조금 복잡한 부분은 LSTM 셀인데, 사실 분해해서 보면 행렬 곱셈 여러 번 반복하는 것에 불과합니다. Eigen 라이브러리 써서 구현하면 되지요. 가볍게 마음 먹고 쓱쓱 구현해서 돌려봤는데, 너무나도 느리게 돌아가서 원인을 파악해보았습니다. LSTM 출력층에서 Lemma를 예측하는 부분이 병목이었습니다. 결국은 행렬 곱셈 크기가 전체 연산량을 결정하는데, LSTM 출력층의 크기는 640이고 Lemma의 vocab size는 약 2만개이므로 (n, 640) x (640, 20000) 크기의 행렬 곱셈을 수행해야합니다. 2만개는 쓸데 없이 너무 큽니다. 아무리 범용적으로 쓰이는 형태라고 하더라도 10개 이상의 lemma를 후보로 가지지 않기 때문에, 2만개 중 5~10개만이 관심있는 결과이기 때문이죠. 그렇다고 해서 적법한 후보가 될 수 있는 lemma 5~10개만을 추려서 곱할 수도 없습니다. 왜냐면 전체 2만개 vocab에 대해 softmax를 취해 확률분포를 구해야하기 때문입니다. 이 계산을 근사하게 근사하는 방법은 없을까요? LSTM 출력에서 lemma를 예측하는 부분의 수식을 다시 한번 살펴봅시다.
$$ P(l, f | O) = softmax\left(W^l \: O\right)_l \cdot softmax\left(W^f \: O \right)_f $$
이 중 관심사는 $softmax\left(W^l \: O\right)_l$ 이 부분입니다. 이걸 좀 더 풀어써보면 (식이 지저분하니 $Y = W^l \: O$로 줄여쓰도록 할게요.)
$$\frac{\exp\left(Y_l\right)}{\sum_i{\exp\left(Y_i\right)}}$$
이 됩니다. 특정 lemma $l$에 대해서만 관심이 있다하더라도 분모에서 모든 $Y_i$에 대해 exp를 계산하여 합해야하기 때문에 결국 Y의 모든 성분을 계산해야만 하는 억울한 상황에 처해있습니다. 그런데 굳이 아주 정확한 값을 알고 싶지 않은 거라면 분모에서 일부 작은 값들은 버려도 되지 않을까요? 특히 exp연산은 큰 값은 엄청 크게, 작은 값은 엄청 작게 만드는 재주가 있습니다. 10만큼 차이 나는 수를 exp에 통과시키면 22000배 차이가 나게 됩니다. 10이상 차이 나는 작은 값들에 대해서는 굳이 $exp(Y_i)$를 계산해서 더해주지 않아도 최종 결과는 큰 차이가 없을겁니다. 즉, 만약 $Y_i$의 최댓값 및 큰 값들만 알아낼 수 있다면 작은 값들은 계산을 생략할 수 있습니다. 계산을 생략하는 부분에 대해서는 굳이 행렬 곱셈을 수행할 필요도 없구요.
근데 어떤 값이 큰 값인지 어떻게 알아낼까요? 결국 큰 값인걸 알아내려면 행렬 곱셈을 해야하는데... 사실 이건 수학만으로는 풀 수 없고, 인간의 언어가 가지는 특성을 활용해야 합니다. 인간의 언어에서는 자주 쓰이는 단어는 굉장히 자주 쓰이고, 그렇지 않은 단어는 굉장히 적게 쓰입니다. (한국어를 예로 들자면, 자주 쓰이는 어휘 20위 권 안은 대부분 조사와 어미가 꿰차고 있습니다.) 이는 어휘의 일종인 lemma에도 통하는 말입니다. 언어 모델은 말뭉치를 학습하면서 자주 등장하는 단어의 확률값은 높이고 드물게 등장하는 단어의 확률값은 낮추는 작업을 하는데요, 그 결과 평균적으로 다음 단어의 확률값과 단어의 사용빈도는 비례하는 경향을 보입니다. 따라서 lemma vocab을 구성할때 고빈도부터 저빈도 순으로 vocabulary를 구성한다면 $Y$ 중 앞쪽 성분들이 평균적으로 큰값을 지니게 되고 뒷쪽 성분들은 작은 값을 지니게 됩니다! 그렇기 때문에 빈도 내림차순으로 정렬한 lemma에 대해서는 $W^l$행렬의 앞쪽 일부분만 사용하여 $\sum_i{\exp\left(Y_i\right)}$를 계산해도 참값과 거의 일치하는 결과를 얻을 수 있습니다.
| 부분 행렬 크기 | Lemma 예측 정확도 |
|---|---|
| 전체 다 사용(=20000) | 92.11 |
| 10000 | 92.13 |
| 5000 | 92.13 |
| 3000 | 92.15 |
| 1000 | 92.14 |
| 500 | 92.13 |
실제 실험 결과, 전체 행렬을 다 사용할 경우와 500~2000 크기의 부분행렬을 사용할 경우의 정확도 차이는 오차 범위 내에 들어갔습니다. 이를 $W^l$ 행렬 크기를 크게 줄일 수 있었습니다.
| 총 분석 시간(ms) | 단어당 평균 분석 시간(ms) | |
|---|---|---|
| Python + tf GPU (GeForce 1660 Super) |
80022 | 10.7 |
| Python + tf CPU (Ryzen 3700X, 8-threads) |
78070 | 10.5 |
| C++ 구현 (Ryzen 3700X, 1-thread) |
200130 | 26.9 |
| C++ 구현 + Softmax 최적화 (Ryzen 3700X, 1-thread) |
29107 | 3.9 |
tf GPU 버전이 예상외로 굉장히 느린데, 이는 앞서 설명한 것처럼 입력 데이터가 batch로 들어오지 않고, 디코딩 역시 한번에 하나씩만 가능하기 때문에 발생하는 문제입니다. 해결책은 입력 데이터가 어느 정도 쌓일때까지 기다렸다가 한꺼번에 처리하거나, RNN이 아닌 다른 모델로 구조를 바꾸는 수 밖에 없습니다. 그러나 C++로 작성해 CPU에서 돌릴 경우 최종적으로 처리시간 단어당 평균 4ms 이내에 도달했습니다. 단일 스레드에도 돌린 결과이기 때문에 병렬화까지 수행하면 몇 배 더 올릴 수 있겠지요. 다만 호스팅 서버의 CPU 코어가 적은 관계로 병렬화 작업은 굳이 하지 않았습니다.
이렇게 Lamonpy가 탄생했습니다!

이렇게 규칙 기반 후보 추출에 (Lemma, Feature) 조합을 동시에 처리하는 언어 모델을 연결해서 라틴어 품사 태거가 탄생할 수 있었습니다. 학습 데이터 부족은 자기 학습을 통해 극복했구요. C++ 구현 코드는 Github에서 살펴보실 수 있습니다. 데모는 살아있는 라틴어 웹사이트에서 제공하고 있으니, 관심 있으신 분들은 해당 페이지를 방문해주세요~ 아직 성능이 조금 부족하기는 하지만, 데이터 추가 확충과 언어 모델 강화라는 확실한 두 가지 개선 방안이 있는만큼 앞으로도 틈틈히 개선해나갈 예정입니다.
사실 라틴어에 적용한 이 방법은, 단어가 규칙적으로 다양하게 변화해서 규칙을 기술하기는 쉬운 반면, 태깅된 학습 데이터를 구하기 어려운 언어라면 범용적으로 적용가능할 것으로 보입니다. 다른 언어들에도 적용가능한 지점이 있는지, 어떤 점을 개선가능한지 좀 더 고민해봐야겠습니다.
- 이 말뭉치에는 고전 시기 라틴어뿐만 아니라 중세/근대 라틴어까지 포함되어 있습니다. 시기에 따라 문법이 조금씩 변화했기 때문에 모든 이를 하나로 뭉뚱그려 사용하는 것은 엄밀하게는 문제가 있는 방법입니다. 다만 대량의 말뭉치를 확보함으로써 얻는 이득이 서로 다른 시기의 텍스트를 섞어씀으로써 발생하는 오염보다는 이득이 클것이라 생각되어 실험에서는 이를 전부 사용하였습니다. [본문으로]
- 비슷한 이유로 한국어로 미리 학습된 임베딩을 만들 때에도 영어와는 다르게 단어를 있는 그대로 넣지 않습니다. 그러면 먹는다, 먹었다, 먹는데, 먹지만, 먹어서 등의 단어가 모두 다른 단어로 인식되어 전반적인 품질이 낮아지기 때문이죠. 그래서 형태소 분석기를 통과시킨 다음 학습시키는게 일반적입니다. [본문으로]
- 그러나 영어에서는 굳이 사전 원형을 찾지 않고 그대로 임베딩을 학습시키기도 합니다. 이는 영어 단어는 변화해봐야 3~5가지 형태로 변하기 때문에, 동일 단어가 서로 다른 형태로 나뉘는 경우가 적어서 가능한 것입니다. [본문으로]
- 사실 일반적으로 자기 학습의 초기 단계에서는 지도 학습 데이터로 모델을 학습시킵니다. 그러나 본 실험에서는 지도 학습 데이터가 아니라 무작위 정답 데이터를 생성하여서 학습시켰기에 엄밀하게는 학습 방법에 조금 차이가 있습니다. 다만 자기 자신을 학습시키는 핵심 아이디어는 동일하게 사용하므로, '자기 학습'이라는 표현을 그대로 사용했습니다. [본문으로]
'프로그래밍 > NLP' 카테고리의 다른 글
| 형태소 분석기의 모호성 해소 성능을 평가해보자 (4) | 2022.03.27 |
|---|---|
| [Kiwi] 문장 같은 고유명사 잘 추출해내기 (2) | 2022.03.20 |
| Kiwi로 한국어 문장 분리하기 (10) | 2021.12.23 |
| 범용적인 감정 분석(극성 분석)은 가능할까 (11) | 2020.07.08 |
| [Python] tomotopy로 Correlated Topic Model 수행하고 시각화하기 (15) | 2020.06.09 |
| [Python] tomotopy로 문헌별 토픽 비중 계산하기 (6) | 2019.12.01 |


댓글 영역