고정 헤더 영역
상세 컨텐츠
본문
이전 글(https://bab2min.tistory.com/666)에서는 언어 모델의 간략한 역사를 살펴봤는데요, 이번 포스팅에서는 한국어 데이터를 이용해서 이전 글에서 다뤘던 모델들을 학습해보고, 직접 평가를 수행하면서 각 모델들이 얼마나 잘하는지, 무엇을 잘하고 무엇을 못하는지 살펴보고자 합니다.
언어 모델을 어떻게 평가할까
정확도
언어 모델은 이전 단어를 바탕으로 다음 단어를 예측해주는 모델이라고 했습니다. 따라서 언어 모델의 성능을 평가하는 가장 간단한 방법은 모델이 예측한 단어들 중 확률이 제일 높은 것이 실제 단어와 얼마나 동일한지를 따져보는 것이지요. 이를 정확도(Accuracy)라고 합니다. 간단한 예로 4개의 단어로 이뤄진 문장 a, b, c, d가 있다고 할 때, 먼저 시작 문맥에서 예측된 다음 단어 $\mathrm{argmax}_x P(x | \mathrm{start})$가 a와 같은지, 그리고 a를 입력했을 때 예측되는 다음 단어 $\mathrm{argmax}_x P(x | \mathrm{a})$가 b와 같은지, 또 a, b를 입력했을때 예측되는 다음 단어 $\mathrm{argmax}_x P(x | \mathrm{a}, \mathrm{b})$가 c와 같은지, 마지막으로 a, b, c를 입력했을때 예측되는 다음 단어 $\mathrm{argmax}_x P(x | \mathrm{a}, \mathrm{b}, \mathrm{c})$가 d와 같은지를 따져볼 수 있겠습니다. 이렇게 총 4개에 대해 따져본 뒤 맞춘 경우를 비율로 계산하여 4개 다 맞췄으면 정확도가 100%, 1개만 맞췄으면 정확도가 25%할 수 있겠습니다.
언어모델을 학습할 때에 사용한 문장을 평가에 사용하는 건 공정하지 않겠죠? 그래서 평가시에는 학습 때는 쓰지 않았던 문장을 투입합니다. 문장들의 단어 수가 총 N개라면 N개 단어 각각에 대해 모델이 예측한 결과와 비교하여 정확도를 쉽게 계산할 수 있습니다.
가능도, 로그 가능도, 단어당 로그 가능도, 혼잡도
그런데 단순히 정확도로 모델을 평가하는 건 부족할 때도 있습니다. 예를 들어 위와 마찬가지로 4단어로 이뤄진 문장 a, b, c, d를 이용해 두 모델을 평가 중이라고 가정해봅시다. 단어 a, b, c를 입력했을때 두 모델이 모두 d를 가장 높은 확률로 예측하는 건 동일하지만, 그 확률은 서로 다를 수 있습니다. 단어 a, b, c를 입력했을 때 두 모델이 구체적으로 예측한 다음단어의 확률이 다음과 같을 수 있겠죠.
| 모델 (가) | 모델 (나) | |
|---|---|---|
| a | 0.01 | 0.24 |
| b | 0.04 | 0.25 |
| c | 0.05 | 0.25 |
| d | 0.90 | 0.26 |
모델 (가)는 아주 확실한 확률로 다음 단어가 d임을 예측했지만, 모델 (나)는 불확실하게 가까스로 다음 단어가 d임을 예측하고 있습니다. 정확도 지표에서는 이 경우 두 모델 다 다음 단어를 정확하게 예측했으니 같은 점수를 받게 됩니다. 그런데 사실 모델 (나)의 경우는 살짝만 운이 나빠도 틀린 답을 낼 수 있는 상황이죠. 이를 반영할 수 있도록 확률 그 자체를 평가 척도로 사용하는 걸 생각해볼 수 있겠습니다.
가능도(Likelihood) 지표는 주어진 문장을 모델이 실제로 어떻게 예측하는 지 그 확률을 계산합니다. 위의 문장 a, b, c, d를 예로 들면 다음과 같습니다:
$$L(\mathrm a, \mathrm b, \mathrm c, \mathrm d) = P(\mathrm a | \mathrm{start}) P(\mathrm b | \mathrm a) P(\mathrm c | \mathrm a, \mathrm b) P(\mathrm d | \mathrm a, \mathrm b, \mathrm c) $$
그런데 확률값은 항상 0~1사이의 값이므로 이를 전부 곱해나가다보면, 이 값은 점점 작아져서 0에 가까워질 것입니다. 그럼 서로 비교하기가 어려우므로 보통 여기에 Log를 취한 로그 가능도(Log Likelihood, LL)를 많이 사용합니다. 로그를 취하면 곱셈은 모두 덧셈이 되고 0~1사이의 확률 값은 $(-\infty, 0]$에 들어오게 됩니다. 훨씬 비교하기 편하겠죠? 단어 개수가 N개인 문장에 대해 일반화하면 다음과 같습니다:
$$LL(x_1, \cdots, x_n) = \sum_{i=1}^{n} {\log {P(x_i | x_1, \cdots, x_{i-1})}}$$
그런데 단어 개수에 따라 이 값은 0에 가까울수도 있고, 엄청 작은 음수가 될 수도 있습니다. 문장 길이에 의해 값의 범위가 크게 달라지는 걸 막으려면 저걸 전부 다 더하는 대신 평균을 내면 좋겠죠? 이렇게 LL을 문장 길이로 나눠 준 값을 단어당 로그 가능도(Per-word Log Likelihood, PWLL 혹은 PLL)라고 합니다. 이 값의 의미를 되새기자면, 평균적으로 언어 모델이 다음 단어를 정확하게 예측하는 확률에 로그를 씌운 것이라고 할 수 있습니다. 즉, 어떤 모델의 단어당 로그 가능도가 -4라는 건, 이 모델이 다음 단어를 평균적으로 $ \exp(-4) \approx 1.83% $ 의 확률로 정확하게 맞춘다는 뜻입니다. LL이나 PLL은 음수로 나오기 때문에 -부호를 항상 붙여주는게 참 귀찮습니다. 그래서 Negative LL처럼 아예 부호를 뒤집어서 -를 떼고 표현하는 경우도 있습니다.
그리고 마지막으로 혼잡도(Perplexity)라는 개념이 있는데, 이는 다음과 같이 정의됩니다(PWLL은 단어당 로그 가능도):
$$\mathrm{Perplexity}(x_1, \cdots, x_n) = \exp( -\mathrm{PLL}(x_1, \cdots, x_n) ) = \exp(-\mathrm{LL}(x_1, \cdots, x_n) / n) $$
단어당 로그 가능도에 마이너스를 붙여 exp에 넣어버린 값입니다. 즉, 모델이 평균적으로 다음 단어를 정확하게 맞추는 확률의 역수로, 모델이 얼마나 혼란스러워하는지를 보여줍니다. 단어당 로그 가능도가 -4인 경우 Perplexity는 $\exp(4) \approx 54.59$로 모델이 다음 단어를 맞추는 정확도가 마치 약 54.59개의 후보에서 1개를 고르는 것과 같다는 것입니다. 즉 PLL과 Perplexity는 같은 대상을 표현만 조금 다르게 한 셈입니다. PWLL은 항상 0보다 같거나 작고, 그 값이 클수록(0에 가까울수록) 좋은 것이고, Perplexity는 항상 0보다 크며, 그 값이 작을수록 좋은 것입니다.
참고로 요즘 등장하는 강력한 언어 모델의 경우 Perplexity는 10~20 정도(PLL은 -2~-3 정도)를 보이고 있습니다. 보통 사람이 사용하는 언어의 어휘 종류가 수 만 가지가 넘는다는 것을 감안하면, 고민해야할 후보를 수 만 개에서 10~20개 정도로 확 줄여버리는 게 얼마나 강력한지 느껴볼 수 있습니다.
목적에 맞는 평가 척도 고안하기
이외에도 언어 모델의 사용 목적에 맞춰 평가 척도를 고안할 수 있습니다. 예를 들어 오타를 교정하기 위해 언어 모델을 만드는 거라면 오타 교정이라는 작업을 이용해 오타 교정 정확도라는 척도를 쓸 수 있겠죠. 단어당 로그 가능도가 높은 언어 모델이라고 항상 목적으로 하는 작업에서 높은 성능을 보이는 것은 아니기 때문에 이렇게 실제 목적에 부합하는 척도를 함께 사용하는 건 중요합니다.
저는 지금 언어모델을 형태소 분석 및 단어 의미 중의성 해소에 적용하는거에 관심이 있으므로, 주어진 전후 맥락 사이에 들어갈 적절한 단어를 고르는 작업을 이용해보려고 합니다. 예를 들자면 다음과 같은 빈칸 채우기 문제를 푸는 것이에요.
나는 치킨을 __었다.
A. 품사 맞추기: 1) 먹/VV 2) 먹/NNG 3) 먹/VX 4) 먹/NA
B. 형태 맞추기: 1) 먹/VV 2) 뛰/VV 3) 묻/VV 4) 걷/VV
위 문장에서 빈칸에 들어갈 적절한 단어를 하나 고르는 것입니다. 문제는 A처럼 형태는 같은데 품사가 다른 경우를 보기로 주거나, B처럼 품사는 같은데 형태는 다른 경우를 보기로 줍니다. 이를 통해 언어 모델이 문법상으로 적절한 단어 배열을 아는지, 또 의미상으로 적절한 단어 배열을 아는지 구별해 낼 수 있습니다. 당연히 보기는 헷갈리도록 해서 난이도를 최대한 높일 겁니다.
빈칸 채우기 작업의 경우 여러 후보 중 하나의 정답을 맞추는 것이므로 전체 문제 대비 모델이 맞힌 문제의 개수로 정확도(Acc)를 계산할 수 있습니다. (이하에서는 언어 모델 자체의 정확도와 빈칸 채우기 작업의 정확도 모두 정확도라고 줄여서 표기합니다. '빈칸 채우기'라고 별도로 작업을 명시하는 경우가 아니면 언어 모델의 정확도를 지칭하는 것이므로 헷갈리지 않으시길 바랍니다.)
그런데 정확도는 정답을 정확하게 맞춘 경우에만 점수를 부여하기 때문에 너무 엄격하므로 상대적으로 관대한 척도인 MRR(Mean Reciprocal Rank)도 함께 사용하도록 하겠습니다. MRR은 여러 후보를 랭킹을 매겨 줄을 세웠을때 실제 정답에 해당하는 후보가 몇 순위에 들었는지를 바탕으로 점수를 계산합니다. 실제 정답이 1순위인 경우 1점, 2순위인 경우 $1/5 = 0.5$점, 3순위인 경우 $1/3 = 0.33%점, $r$순위인 경우 $1/r$점을 부여합니다. 모든 문제에 대해 이 점수를 평균낸 값이 MRR이 됩니다. Acc는 정답이 1순위인 경우에만 1점, 나머지엔 0점을 부여하는 셈이므로 Acc값은 항상 MRR보다 같거나 작습니다.
언어 모델 비교 결과
언어 모델을 학습하기 위해 큰 크기의 말뭉치가 필요합니다. 저는 모두의 말뭉치에서 제공하는 형태 분석 말뭉치를 사용하기로 했습니다. 텍스트들이 형태소 단위로 분석되어 있어서 형태소 단위의 언어 모델을 학습하는데 제격이기 때문입니다. 구어체와 문어체 데이터를 모두 사용했으며, 형태소는 전체 데이터에서 10회 이상 등장하는 것만 추려서 사용했습니다. 추리고 나니 약 49000개의 형태소가 남았고, 10회 미만 등장한 형태소들은 그 품사에 맞춰 [UNK]/NNG, [UNK]/VV 와 같이 미등재 형태소를 나타내는 특수 태그로 대체했습니다. 마지막으로 전체 데이터를 임의로 뒤섞은 뒤 9:1로 나누어 90%는 학습셋(약 2759만 단어)으로 10%는 평가셋(약 306만 단어)으로 구성했구요.
이전 글(https://bab2min.tistory.com/666)에서 소개한 Kneser-ney n-gram model과 RNN 모델 중 GRU, 그리고 GRU에 Self-attention을 더한 모델에 마지막으로 Transformer 모델 중 GPT를 비교 대상으로 삼았습니다. n-gram model의 경우 딱히 학습이라 할 단계가 없고 말뭉치에 대해 빈도 조사만 수행하면 되지만, 나머지 신경망 계열 모델들은 학습이 필요하므로 하이퍼파라미터를 최대한 잘 선정하고 가능한 최선의 방법으로 학습을 수행했습니다. 무작정 큰 모델을 학습하기보다는 실용적인 목적에서 가볍고 빠르게 돌릴 수 있는 언어 모델을 확인할 수 있도록, 작은 모델을 위주로 탐색해 봤습니다.
전반적인 성능 비교

먼저 Kneser-ney n-gram 모델의 결과입니다. 사실 1-gram은 모든 단어를 독립으로 간주하므로 언어 모델로 치기도 어려운데요, 그래도 언어 모델이 가장 나쁠 경우 어디까지 떨어질 수 있나를 살펴볼 수 있으므로 베이스라인으로 삼기에 아주 적절합니다. 자명하게도 n이 커질수록 Negative PLL값은 더 작아지고, 정확도는 더 높아지는 걸 볼 수 있습니다.

다음은 GRU 모델입니다. GRU 모델의 성능을 결정짓는 중요한 요소는 각 단어의 임베딩 크기와 GRU셀의 메모리(상태) 크기입니다. 임베딩 크기는 각 단어의 의미를 몇 개의 숫자로 나타낼지를 결정하며, 당연히 클수록 단어의 더 세밀한 의미를 표현해 낼 수 있습니다. GRU 셀의 메모리 크기는 모델이 이전까지 입력된 히스토리를 몇 개의 숫자로 기억하고 있을지를 결정합니다. 당연히 클 수록 더 많은 정보를 기억하고 있을 수 있구요. 위의 차트에 표시된 32d, 48d는 임베딩 크기이며, 메모리 크기는 임베딩 크기의 2배로 설정했습니다. 비교용으로 Kneser-ney 4-gram 모델의 결과도 함께 표현했는데요, 임베딩 크기가 64 이상인 경우 대략 4-gram 모델의 성능을 따라잡기 시작합니다. 그리고 여기서도 자명하게 임베딩 크기가 커질 수록 모델이 더 정확해지는 걸 확인할 수 있습니다.

GRU에 Self-attention을 붙여서 모델이 이전에 출현한 단어들 중 원하는 단어의 정보에 다시 접근할 수 있도록 개선한 모델입니다. 그런데 단순 GRU 모델과 성능 차이가 사실상 없네요. GRU 셀을 2개를 붙여서 2 layer로 구성할 수 있지만(차트에서 2l이라고 표기된 항목들) 성능 향상이 크지는 않습니다. 64d 2l보다는 그냥 128d을 쓰는게 낫고, 128d 2l보다는 256d를 쓰는게 낫네요.
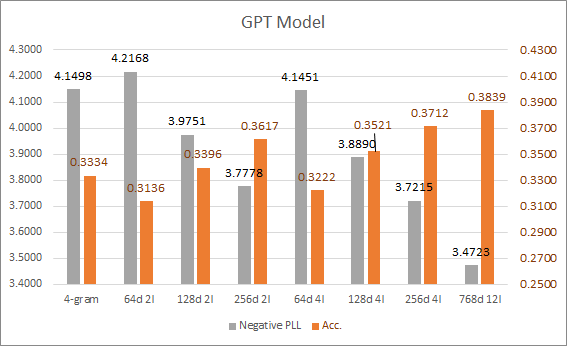
마지막으로 GPT 모델입니다. GPT 역시 GRU와 마찬가지로 각 단어의 임베딩 크기와 레이어의 개수가 성능에 큰 영향을 미칩니다. 최대한 비슷한 크기의 GRU 모델과 비교하기 위해 (64d, 128d, 256d) x (2l, 4l) 조합에 대해서 평가해봤습니다. 그리고 GPT-2 Small 크기인 768d 12l에 대해서도 테스트해봤습니다. 테스트에 사용한 모델 중 가장 큰 모델이기에 이 녀석의 결과는 이번 실험에서 도달할 수 있는 정확도의 상한치를 보여준다고 할 수 있겠네요 (학습에 사용한 데이터 크기가 작은지라 실제 GPT-2 small 모델은 저보다도 더 높은 성능을 달성할 수 있음에도 저 정도에서 멈췄다고 보는게 타당할 것 같아요). GPT 모델의 경우 임베딩의 크기가 작은 경우에는 GRU보다도 떨어지는 결과가 나옵니다. 그리고 레이어의 개수가 증가함에 따라 서서히 성능이 개선됩니다. 작은 임베딩에 적은 레이어를 써야하는 상황이라면 GPT보다는 1레이어짜리 RNN 모델이 훨씬 유리할 수 있겠습니다.
단어 빈도별 성능 차이
로그 가능도와 정확도를 이용해서 다양한 언어 모델의 전반적인 성능을 평가해봤는데요, 각각의 언어 모델이 작동하는 방식이 사실 크게 다르기 때문에 전반적인 성능으로 드러나지 않는 차이점이 있을지도 모릅니다. 그래서 위에서 제안한 빈칸 채우기 문제를 이용해 각 모델별 특징을 좀 더 자세하게 알아보았습니다. 먼저 동일한 품사 내에서 후보를 주고 빈칸을 채우도록 한 경우입니다. 빈칸으로 치환된 단어의 빈도에 따라 모델이 다른 성능을 보일 것 같아서, 결과를 빈도에 따라 나눠봤습니다. 상위 100단어는 최상위빈도, 그 다음 500단어는 차상위빈도, 그 다음 2500단어는 중위빈도, 그 다음 12500단어는 차하위빈도, 나머지 모든 단어는 최하위빈도로, 총 다섯 덩어리로 분류하여 통계를 내보았습니다.

먼저 최상위 및 차상위 결과를 봅시다. 최상위 단어의 경우 2-gram에서 4-gram으로 가면서 MRR은 하락하는데, Acc는 상승하는 특별한 패턴을 보이고 있습니다만 그 폭이 작아서 유의미하다고 보긴 어렵네요. GRU계열 모델의 경우 64d 이상부터는 4-gram을 앞서는 모습을 보여줍니다. 이는 위에서 언어모델 PLL 평가가 보여주었던 결과와 일치합니다.

그런데 중하위 빈도 단어에 대해서는 사뭇 다른 결과가 나옵니다. 중위에서는 256d만이 4-gram을 간신히 앞섰으며, 하위권에서는 어떤 GRU모델도 Kneser-ney n-gram 모델을 앞서지 못하고 있습니다. 특히 최하위권의 Acc는 0.003~0.013 사이에 위치해서 사실상 정답을 전혀 못 맞추고 있네요. (찍었을 경우 대략 0.006 정도의 Acc가 나옵니다. 찍느니만도 못한 경우도 있다는거죠.) GRU 모델이 중하위권에서 죽을 쓰는 이유는 신경망 모델의 학습 과정에서 찾아볼 수 있습니다. n-gram 언어 모델의 경우 산출된 통계를 그대로 사용하기 때문에 소수 등장한 패턴이라도 일단 전부 기록됩니다. 반면 신경망 모델의 경우 데이터를 계속 입력받으며 패턴을 학습해나가야하기에 학습데이터에서 소수 등장한 단어들은 학습에 참여할 기회가 적을 수 밖에 없습니다. 반면 고빈도 어휘들은 자주 등장하기 때문에 계속 학습이 되구요. 모델의 크기는 한정되어 있기 때문에 모든 패턴을 다 학습하는건 불가능하고 자주 반복되는 패턴에 대해서만 집중적으로 학습이 됩니다. 결국 저빈도 어휘들은 노이즈로 간주되어 무시되는 셈입니다. 물론 이 덕분에 일반화 능력을 획득할 수 있는 것이라 일장일단이 있다고 봐야하겠네요.
신경망 모델이 중하위 빈도 단어들에 대해서도 높은 성능을 내도록 하려면 모델의 크기를 키우고, 저빈도 단어가 포함된 학습 데이터를 보강하면 됩니다. 불행히도 이번 실험에서 학습데이터는 고정되어 있는 상황이기 때문에 좀 더 큰 모델인 2-layer GRU와 GPT를 추가로 빈칸채우기 작업에 투입해봤습니다.


당연하게도 가장 큰 모델인 GPT Small (768d 12l)가 전반적으로 제일 좋은 결과를 보였습니다. 특히 모델이 커질수록 중하위권 단어에 대해서 정확도가 올라가는 것을 볼 수 있는데요, 이를 통해 작은 모델이 놓치게 되는 저빈도 단어에 대한 정보들을 큰 모델은 더 잘 학습한다는 걸 알 수 있습니다. 그러나 가장 큰 모델인 GPT Small에서도 여전히 차하위/최하위 빈도에서는 n-gram 모델보다 약한 모습을 보이는 경우가 있네요. 이는 GPT Small 크기의 한계라기보다는 학습 데이터의 부족에서 기인하는걸로 보이나, 정확히는 모르겠네요. 여기서 확실히 확인할 수 있는 것은 몇 천만 단어 수준(1~2GB)의 말뭉치로 학습한 RNN, GPT 모델은 저빈도 단어에서 n-gram 모델보다 정확도가 낮을 수 있다는 것입니다.
품사별 성능차이
빈칸으로 대체된 형태소의 품사에 따라 성능에 차이가 있지 않을까 싶어서 이에 대해서도 실험을 진행했었는데, 사실 빈도별 성능 차이로 설명 가능한 결과가 나왔습니다. 즉, 자주 쓰이며 품사 내에 포함된 형태소의 가짓수가 비교적 제한적인 조사 / 어미 / 보조용언 / 수사 / 대명사들에 비해 명사 / 동사 / 형용사처럼 포함된 형태소의 가짓수가 무궁하여 각 형태소의 빈도가 상대적으로 적은 경우에 n-gram 모델이 더 높은 정확도를 보였습니다. GRU나 GPT의 경우 마찬가지로 모델의 크기를 키울수록 이런 품사에 대한 정확도가 크게 개선이 되는 경향을 보였구요. 이에 대해서는 장황하게 별도의 차트를 첨부하지는 않겠습니다.
앙상블 - 서로 다른 모델의 장점을 합치자
지금까지 세 가지 척도(정확도, 단어당 로그 가능도, 빈칸 채우기 정확도)를 이용해서 언어 모델의 성능을 평가해봤는데요, 학습 데이터가 제한적일 경우 n-gram과 신경망 기반의 언어 모델이 서로 다른 경향성을 보인다는 걸 알 수 있었습니다. n-gram 모델의 경우 저빈도 어휘에 대해서 상대적으로 높은 정확도를 보인 반면 GRU나 GPT와 같은 신경망 모델의 경우 고빈도 어휘에 대해서 높은 일반성을 보였습니다. 즉, 각자가 잘하는 부분이 서로 다른 셈인데요 이 둘의 장점만을 취할 수 있는 좋은 방법이 있습니다. 앙상블(Ensemble)이라는 건데요, 여러 모델을 합쳐서 더 강력한 모델을 만드는 방법입니다.
여러 언어 모델을 어떻게 앙상블할 수 있을까요? 현실에서 많이 겪어보셨겠지만, 둘 이상을 합칠 때 시너지가 나게 하는건 생각보다 어렵습니다. 두 모델이 각자 잘하는 것만 취해서 합치려고 했는데, 엉뚱하게 둘의 단점만 모여서 하나만도 못한 상황이 나올 수도 있잖아요~. 의외로 방법은 간단한데요, 두 모델이 예측한 확률을 적당한 비율로 섞어주면 됩니다.
| 모델 (가) | 모델 (나) | (가), (나)의 평균 | |
|---|---|---|---|
| a | 0.01 | 0.26 | 0.13 |
| b | 0.04 | 0.25 | 0.15 |
| c | 0.05 | 0.25 | 0.15 |
| d | 0.90 | 0.24 | 0.57 |
모델 (가)와 (나)가 다음 단어를 예측한 결과가 위와 같다고 해봅시다. 실제 정답은 d인 상황이구요. 모델 (가)는 d를 다음 단어로 예측하지만, (나)는 a를 예측하고 있습니다. 두 모델을 합친다고 할 때 어떻게 d가 더 괜찮은 예측인지 알 수 있을까요? 이는 모델이 예측한 확률값을 보면 됩니다. 모델 (가)는 90%의 확률로 d를 예측하고 있고, (나)는 26%의 확률로 a를 예측하고 있거든요. 즉, (가)는 상당히 자신감 있게 다음 단어를 예측하고 있는 반면 (나)는 간신히 찍고 있는 상황이라는 걸 알 수 있습니다. 그래서 모델이 예측한 정답의 확률값을 신뢰도(confidence)라고도 부릅니다. 이게 1에 가까우면 모델이 아주 자신감 있게 정답을 예측하고 있는거고, 작으면 불확실하게 예측하고 있는 것이기 때문이죠. 따라서 두 모델이 예측하는 확률을 적당한 비율로 섞어주면(위 예시에서는 1:1로 섞었습니다. 즉 평균이죠.) 신뢰도가 높은 후보의 경우 상대적으로 높은 확률이 유지되고, 신뢰도가 낮은 후보의 경우 다른 모델의 결과와 뒤섞여 확률값이 변동됩니다. 결국 두 모델 중 더 자신있어하는 모델의 결과가 최종 정답 예측에 많이 반영되는 셈이죠. 그래서 언어 모델의 앙상블은 서로 전공 분야가 다른 두 사람이 함께 문제를 푸는 것과도 같습니다. 자기가 아는 분야가 나왔을때는 확실하게 주장해서 정답을 맞추고, 잘 모르는 분야일때는 상대방의 의견을 구하는거죠.
그럼 Kneser-ney n-gram 모델과 GRU & GPT 모델을 앙상블한 결과를 살펴봅시다.


먼저 LL 결과입니다. 제일 왼쪽의 Single KNLM은 앙상블없이 3-gram과 4-gram을 단독으로 사용할 결과이고, 나머지들은 신경망 모델을 단독으로 사용할 경우(Single), 3-gram과 앙상블할 경우(+ 3-gram), 4-gram과 앙상블할 경우(+ 4-gram)의 성능을 보여줍니다. 3-gram를 단독으로 쓸 경우 NPWLL이 약 4.192정도이고 GRU 32d를 단독으로 쓸 경우 4.420이지만, 이 둘을 앙상블해서 사용하면 4.051로 LL이 크게 개선됩니다. 자명하게도 앙상블 후의 성능은 앙상블에 사용한 모델들의 성능이 좋을수록 좋습니다. 다만 신경망 모델이 커질수록 n-gram을 앙상블한 경우의 성능 향상폭이 줄어드는데, 이는 앞서 확인한것처럼 신경망 모델 크기가 커질수록 저빈도 어휘에 대한 학습 능력이 향상되기에 n-gram이 채워줄 수 있는 부분이 줄어들기 때문으로 볼 수 있습니다.
GRU 64d에 4-gram 앙상블을 한 경우 GPT 128d 4l와를 단독으로 쓰는 것과 거의 비슷한 성능을 보이는데요, GRU 64d의 연산량이 GPT 128d 4l의 1/10도 안 되기에, 메모리는 충분하지만 연산 속도가 부족한 경우 GRU 64d + 4-gram 조합으로 GPT 128d 4l을 대신할 수 있을지도 모릅니다. 메모리를 많이 차지하는 n-gram 모델과 연산량이 많은 신경망 모델을 적절히 조합함으로써 적당한 성능에 가벼운 모델을 만드는것도 가능하겠죠.
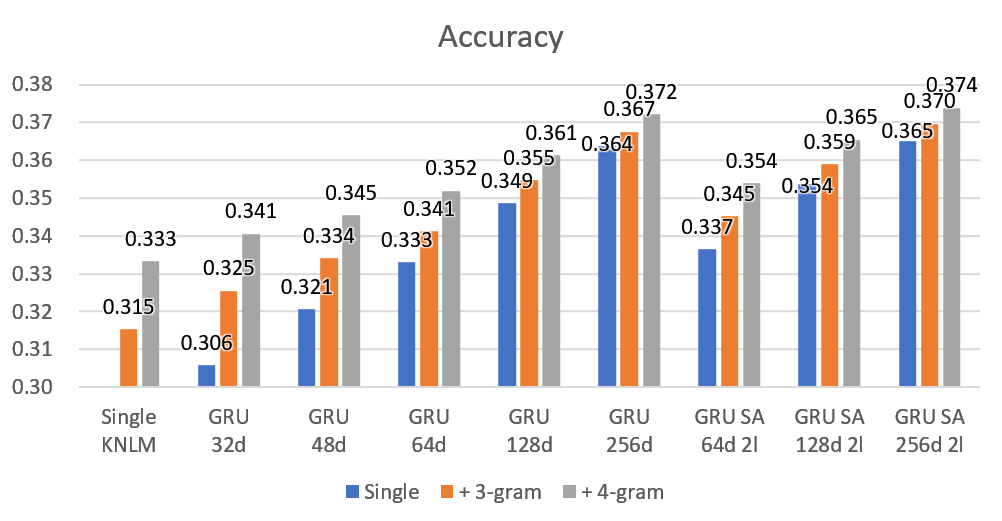

언어모델 정확도도 로그 가능도와 거의 유사한 결과가 나옵니다. GPT 768d 12l과 같이 크고 뛰어난 모델에서도 n-gram과의 앙상블이 약간이나마 효과가 있네요. 역시 아무리 똑똑한 모델이라도 실수하는게 있을 수 있으므로 부족함을 인정하고 남들에게 도움을 구할 줄 알아야하나봅니다.
결론
몇 가지 실험을 통해 통계기반 n-gram 언어 모델과 신경망기반 GRU, GPT 언어 모델의 특성을 살펴봤습니다. 요약해보면 다음과 같겠습니다.
- n-gram 언어 모델의 경우 저빈도 어휘에 대해 상대적으로 높은 성능을 보인다. 대신 n이 커질수록 메모리 사용량이 기하급수적으로 증가한다.
- 신경망 기반 언어 모델의 경우 중~고빈도 어휘에 상대적으로 높은 성능(+일반화)을 보인다. 모델이 커질수록 연산량이 크게 늘어난다.
- n-gram과 신경망 기반 언어모델을 앙상블할 경우 성능을 향상시킬 수 있으며, 성능 향상폭은 신경망 모델이 작을수록 더 큽니다.
'그냥 공부' 카테고리의 다른 글
| 어떤 언어 모델이 좋을까 - 언어 모델의 간략한 역사 (1) | 2021.06.22 |
|---|---|
| [토픽 모델링] Generalized DMR 토픽 모델 (34) | 2020.06.06 |
| [토픽 모델링] Dynamic Topic Model (13) | 2020.05.10 |
| [토픽 모델링] 토픽에 자동으로 이름 붙이기 (8) | 2020.03.19 |
| 그림으로 깁스샘플링 이해하기 (7) | 2020.01.03 |
| [기계 학습] Mean Shift 클러스터링 (5) | 2019.09.04 |


댓글 영역